

Assem-VC
![]()


Assem-Singer
![]()
안녕하세요! MINDsLab Brain의 음성합성 연구를 담당한 김강욱입니다.
오늘은 저희 Brain 팀에서 출판한 논문인 Assem-VC[1]와 Assem-Singer[2]를 소개드리는 시간을 가지려 합니다!
올해 Brain에서 출판한 논문, Assem-Singer가 작년 12월에 열린 NeurIPS의 Machine Learning for Creativity and Design Workshop 에 구두 발표로 승인되었다는 소식에 이어, Assem-VC 또한 올해 5월에 열린 국제신호처리학회 ICASSP 2022 에 게재 승인되었다는 기쁜 소식이 들려왔습니다!
두 논문은 이름도 비슷하고, 실제로 비슷한 모델 구조를 공유하지만 풀어내고자 했던 문제와 풀어나가는 방식에서 차이점을 갖고 있습니다. 오늘은 각각의 연구가 어떤 문제를 풀고자 했고, 어떻게 풀어냈는지를 위주로 두 논문을 소개드리려 합니다. 이 블로그를 읽기 전에 데모 페이지

Assem-VC: 더 자연스럽고 대상 화자와 비슷한 음성 변환을 향해
"명탐정 코난"의 나비 넥타이를 아시나요?
유명한 탐정을 마취총으로 잠재운 코난은 나비 넥타이를 통해 유명한 탐정의 목소리를 내며 자신의 추리를 펼쳐가죠. 여기서 나비 넥타이는 코난의 목소리를 유명한 탐정의 목소리로 변환하는 역할을 합니다. 이러한 작업을 음성 변환(voice conversion)이라 하는데요! 오늘 설명할 Assem-VC[1] 역시 이 음성 변환을 위해 설계된 모델입니다. 위 코난의 예시에서는 코난의 목소리가 source speech, 변환하고자 하는 대상인 유명한 탐정의 목소리는 target voice가 되는 것이죠!
Assem-VC는 이 source speech와 target 화자의 single utterance를 입력받아, source speech의 화자 특성(speaker identity)를 제외한 특성(linguistic information, rhythm, pitch 등)을 유지하고, 이를 target speaker의 화자 특성으로 합성하는 모델입니다. Assem-VC의 구조는 아래 그림과 같습니다.
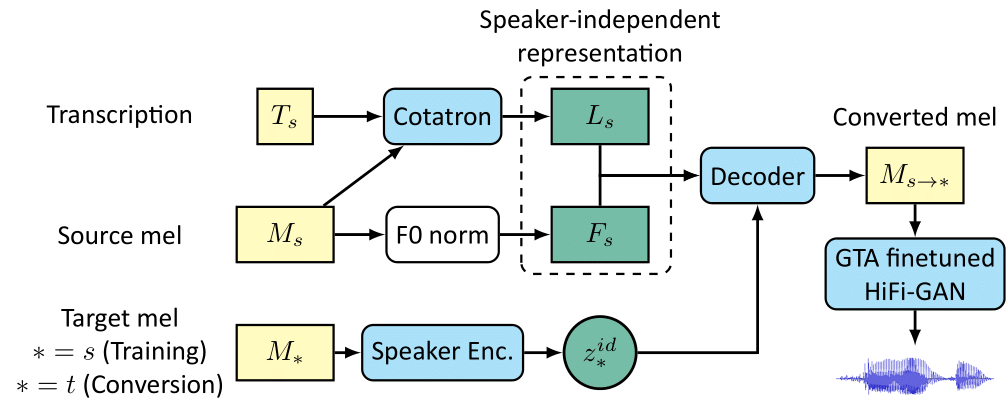
Assem-VC에 필요한 입력은 source speech와 그의 transcript, target speech입니다. source speech와 target speech는 mel-spectrogram의 형태로 변환되어 입력됩니다. Source speech로부터 보존되어야 할 정보는 linguistic information, rhythm, pitch입니다. Source speech에서 이들로부터 화자 정보를 최대한 배제한 형태로 인코딩해야 target speaker로부터 뽑아낸 화자 특성 (speaker identity)와 합쳐져 원하는 목소리를 합성하기 용이합니다. 아래에서는 각 정보를 어떻게 인코딩했는지에 대하여 설명하겠습니다.
- Linguisitic information과 rhythm:
- Source speech의 linguistic한 정보는 가장 화자에 독립적인 정보인 텍스트, 즉 transcript의 도움을 받아 인코딩합니다. 같은 언어를 쓸 수 있다는 가정 하에, 모든 사람은 어떠한 텍스트든 읽을 수 있으니 텍스트는 가장 화자에 독립적인 정보입니다. Assem-VC는 Cotatron[3]이라는 모듈을 이용해 source speech와 transcript 사이의 alignment를 구하고, 이를 통해 linguistic한 정보 를 인코딩합니다. 이 과정에서 특정 프레임에서 어떤 텍스트를 읽었는지의 정보 또한 들어있기 때문에, 에는 rhythm 정보 또한 포함되어 있습니다.
- Pitch와 rhythm:
- Source speech의 pitch 정보는 fundamental frequency, 즉 F0를 인코딩했습니다. 한편 이 F0값 자체는 화자의 음역대에 영향을 받기 때문에, 우리는 화자의 F0 범위를 먼저 구한 후 평균과 표준편차를 이용해 정규화합니다. 이 과정을 통해 화자 종속적인 F0를 최대한 화자 독립적인 로 만들 수 있습니다. 마찬가지로 rhythm에 대한 정보가 포함됩니다.
이렇게 화자 독립적으로 인코딩한 정보들, 와 를 화자 독립적인 representation으로 두고 target speaker의 화자 특성을 더해 원하는 목소리로 만들어냅니다.
그런데 과연 이 인코딩들이 정말 화자 독립적일까요? 우리는 이 위에 각 피쳐가 어떤 화자로부터 나왔는지를 분류하는 classifier를 훈련시키고, 이의 test accuracy를 측정해 보았습니다.
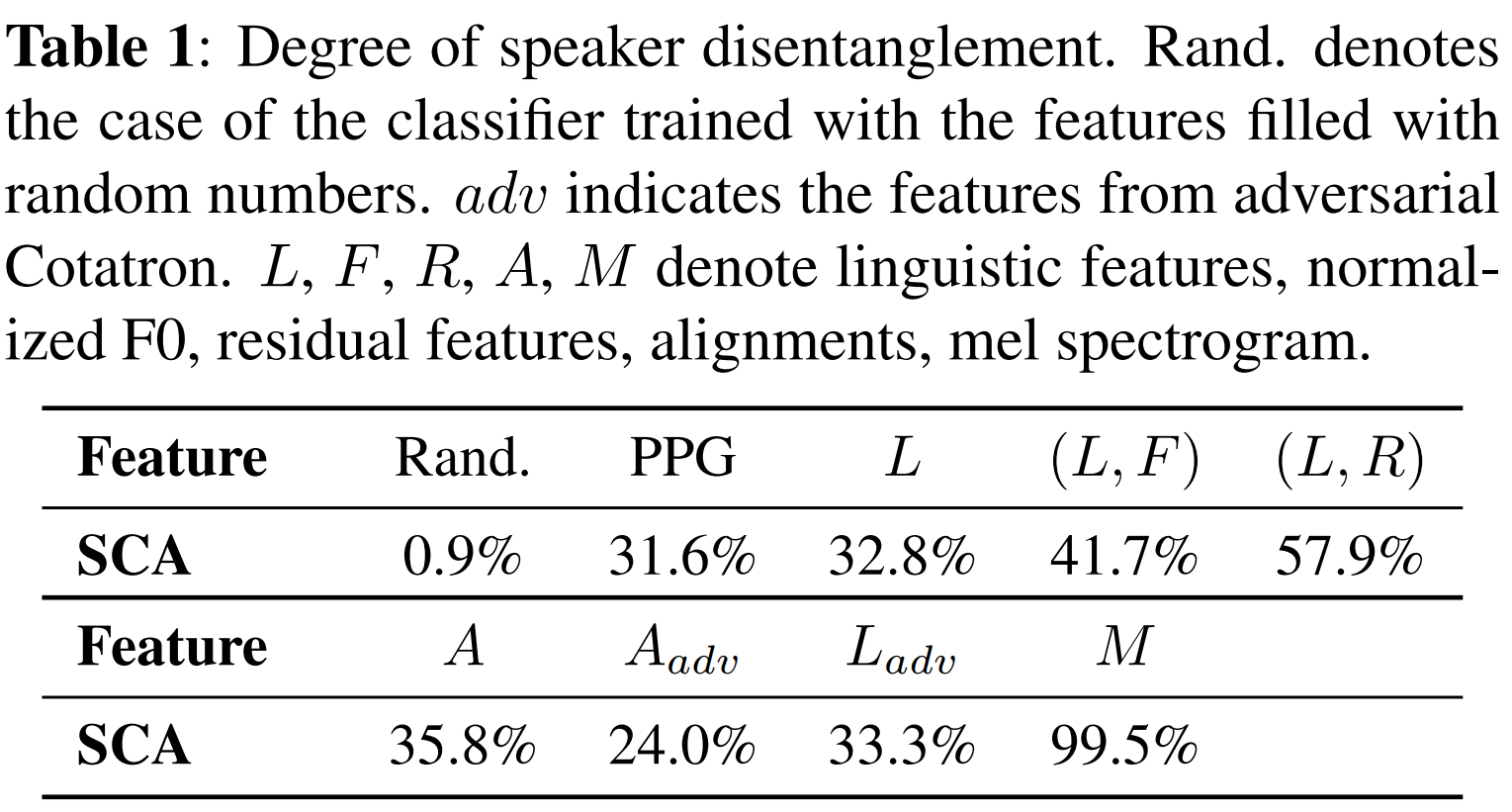
위 표에서 볼 수 있듯이, 와 는 random guessing인 0.9%에 비해 확연히 높은 accuracy를 갖습니다. 이는 여전히 화자 정보가 많이 포함되어 있다는 뜻인데요. 위에서 설명한 rhythm 또한 화자를 추측할 수 있는 정보이기 때문이고, 이 rhythm이 와 에 포함되어 있기 때문에 accuracy가 높게 나온 것입니다.
Assem-VC에서 인코딩한 와 는 Cotatron에서 사용한 feature인 residual feature보다 화자에 독립적이므로, 더 좋은 퀄리티의 음성 합성이 가능할 것으로 기대됩니다! 이렇게 만들어낸 Assem-VC의 음성 변환 성능은 아래 표에서 보실 수 있습니다.
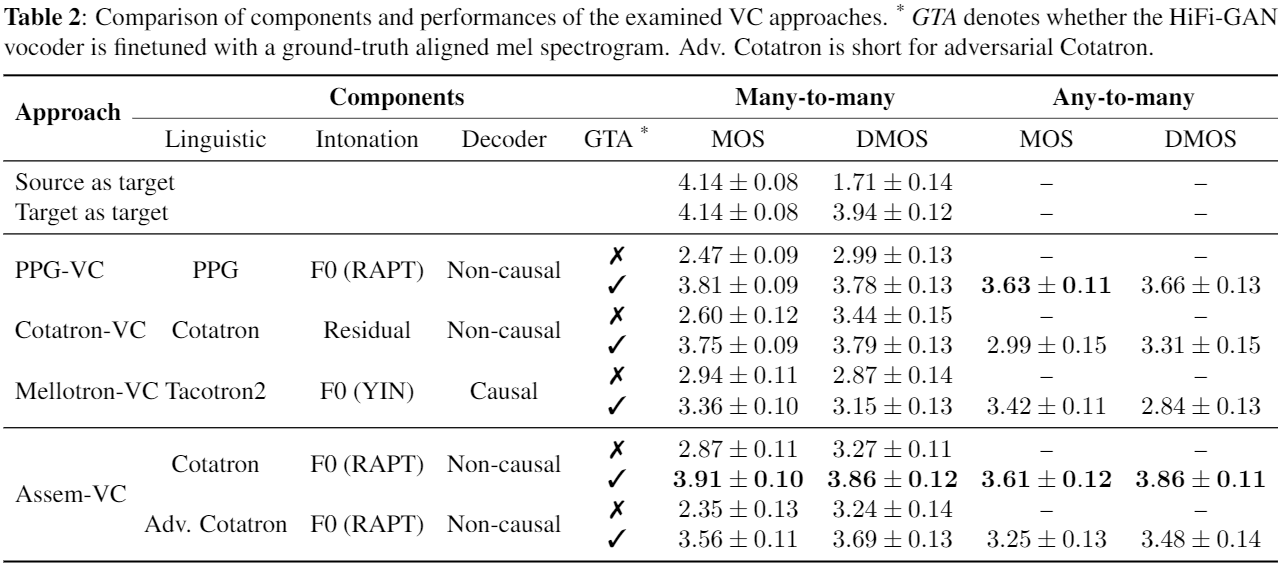
Assem-VC는 자연스러움(naturality)과 화자 유사도(speaker similarity) 측면에서 기존 baseline인 PPG-VC, Cotatron-VC[3], Mellotron-VC[4] 보다 더 높은 mean opinion score (MOS)를 갖습니다. 학습 도중에 본 적 없는 화자의 목소리를 source speech로 받는 any-to-many 에서는 자연스러움에서 성능이 떨어지는데, 이는 cotatron을 화자 혹은 노이즈에 robust하게 만드는 등의 시도가 필요할 것으로 생각하고 있습니다.
실제로 Assem-VC를 통해 음성변환을 진행한 샘플은 여기에서 들어보실 수 있습니다. 특히 한국에서 유행했던 음성들을 이용해 재밌는 샘플들도 몇 개 올려두었으니 한 번 들어보세요 ㅎㅎ
Assem-Singer: 음악적 지식 없이 사람의 노래소리를 마음껏 다루다
Assem-VC 연구를 하며, 음성 변환의 성능이 점점 실제 사람이 말하는 것과 가까워지고 있다는 생각이 들었습니다. 또 이러한 생각도 했습니다. "Assem-VC가 사람이 부른 노랫소리인 singing voice에도 적용 가능할까? 적용 가능하다면 어떤 일들을 할 수 있을까?"
고민하던 중 찾은 답이 바로 이 논문, Controllable and Interpretable Singing Voice Decomposition via Assem-VC[2] 입니다.
저희가 착안했던 Assem-VC의 주된 특징은 다음과 같습니다:
- Text와 speech가 입력되었을 때 둘 사이의 alignment를 estimate하고, 이를 통해 linguistic feature를 출력한다.
- Pitch 정보는 F0를 추출해 encoding한다.
- 위에서 estimate한 정보와 target speaker identity를 이용해 타겟 화자의 음성을 생성한다.
Assem-VC 원 논문에서는 위 특징 중 화자의 목소리를 바꾸어 voice conversion을 수행할 수 있었습니다. 저희는 위 과정에서 encoding되는 다른것들도 조작을 시도했습니다. encoding된 linguistic information과 pitch information을 manipulate한 뒤 합성하면, 주어진 음성을 저희 마음대로 조작하는 것이 가능합니다. 이렇게 저희는 speaker identity뿐만 아니라, text, pitch 또한 조작할 수 있게 되었습니다. 또한 encoding된 feature를 시간축 방향으로 interpolate해서 rhythm까지 조작할 수 있죠. 아래 그림은 reference signal과 각각 linguistic content (text), rhythm, pitch를 조작한 후 재합성한 mel spectrogram을 나타냅니다.

이렇게 저희가 정의했던 speech의 4가지 요소, linguistic information, rhythm, pitch, speaker identity를 manipulate할 수 있게 되었습니다. 저희는 실험을 통해 Assem-VC의 alignment가 적은 양의 singing voice dataset에도 adapt 가능함을 알아냈고, speech가 아닌 singing voice에 대해 위 4가지 요소를 manipulate하는 방향으로 연구를 진행했습니다.
Assem-singer의 구조는 아래와 같습니다.
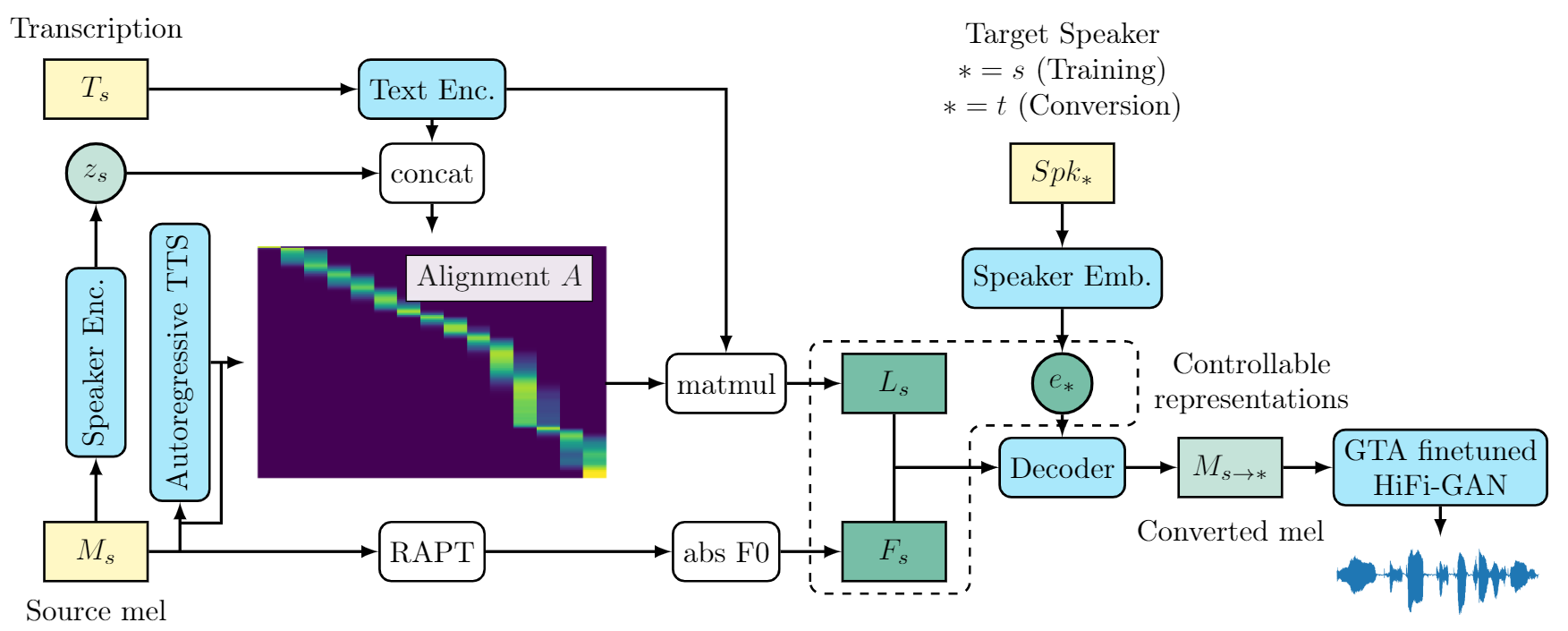
Assem-VC와의 구조적인 차이점은 F0를 화자별로 normalize하지 않고 절대적인 값을 그대로 사용해 manipulate하기 편하게 했고, 화자별 data 양이 적어 speaker encoder 대신 speaker embedding을 사용했다는 점입니다.
위 구조를 통해 주어진 화자의 singing voice의 linguistic information, rhythm, pitch, speaker identity를 manipulate할 수 있었습니다. 또한 저희는 원본 singing voice와 완벽하게 synchronize된 rhythm으로 pitch만 조절할 수 있다는 점에 착안했고, 주어진 singing voice를 활용해 duet을 만들기도 했습니다. 샘플은 여기에서 들어보실 수 있습니다.
위 architecture는 singing voice를 조절하고 싶으나 음계, 리듬 혹은 MIDI에 대한 지식이 없는 general public들도 간단한 editing 혹은 자신의 목소리를 통해 다양한 특성을 조작한 singing voice를 합성해 낼 수 있다는 점에서 NeurIPS의 Machine Learning for Creativity and Design Workshop에서 좋은 평가를 받았습니다.
저의 singing voice data 또한 2분 정도 녹음을 한 뒤 데이터에 포함시켜서 학습했더니 저의 목소리로도 manipulation이 가능했습니다! 제가 노래를 잘 부르는 편이 아닌데도 전문가들이 녹음하고 정제한 데이터와 동일하게 manipulation이 가능해서 흥미로웠습니다.
마치며
이상으로 Assem-VC와 Assem-singer, 두 가지 연구에 대한 설명을 모두 드렸습니다. 위 두 연구의 가장 큰 병목은 speech 혹은 singing voice의 transcript가 필요하다는 점입니다. 또한 transcript가 정확해도 speech나 singing voice에 noise가 껴있을 경우 alignment가 제대로 estimate되지 않는 것도 이 연구의 한계점입니다. 위 둘을 개선하기 위해 automatic speech recognition을 통해 transcript를 얻고, cotatron을 inaccurate text 및 noise에 robust한 aligner로 대체한다면 in the wild에서도 잘 작동하는 system이 될 것 같다는 생각이 들었습니다.
이상으로 저희 연구에 대한 간략한 소개를 마칩니다. 읽어주셔서 감사합니다!
참고 문헌
- Kang-wook Kim, Seung-won Park, Junhyeok Lee, Myun-chul Joe. "Assem-VC: Realistic Voice Conversion by Assembling Modern Speech Synthesis Techniques" arXiv preprint arXiv:2104.00931 (2021). [arxiv]
- Kang-wook Kim, Junhyeok Lee. "Controllable and Interpretable Singing Voice Decomposition via Assem-VC" arXiv preprint arXiv:2110.12676 (2021). [arxiv]
- Seung-won Park, Doo-young Kim, Myun-chul Joe. "Cotatron: Transcription-Guided Speech Encoder for Any-to-Many Voice Conversion without Parallel Data" arXiv preprint arXiv:2005.03295 (2021). [arxiv]
- Rafael Valle, Jason Li, Ryan Prenger, Bryan Catanzaro. "Mellotron: Multispeaker expressive voice synthesis by conditioning on rhythm, pitch and global style tokens" arXiv preprint arXiv:1910.11997 (2019). [arxiv]