
KDD Workshop on Machine Learning in Finance
Minsuk Kim, Gyeongmin Kim, Byungchul Kim, Junyeong Yong, Jeongwoo Park. "BIRP: Bitcoin Information Retrieval Prediction Model Based on Multimodal Pattern Matching"
KDD Workshop
BIRP: Bitcoin Information Retrieval Prediction Model Based on Multimodal Pattern Matching
안녕하세요, 마인즈랩 BRAIN NLP팀에서 근무하고 있는 김민석입니다. 이번에 KDD workshop에 제출한 작업물에 대해서 이 블로그 포스트를 통해 간략하게 설명해보려합니다. 이전의 제 블로그 포스트 CBITS처럼 논문의 모든 부분을 설명한다기보다 중요한 부분만 간략하게 설명할 예정이니 자세한 내용은 논문을 통해 확인해주시면 감사하겠습니다. 이번 포스트는 이전 CBITS에서 소개한 한글 크립토 언어모델과 트레이딩 봇 프레임워크를 활용해서 이전 블로그 포스트 내용을 아시면 이 포스트도 읽는데 도움이 될 것 같습니다. 추가적으로 CBITS를 최근에 거의 한달간 (대략 3월 18일 ~ 4월 18) 실전투자를 돌리면서 수익률을 기록해둔 페이지가 있는데 여기서 확인해보실 수 있습니다. 실투를 진행하면서 어떻게 봇을 고도화 시킬 수 있는지에 대한 많은 아이디어들을 얻었습니다. 그리고 한글 크립토 언어모델들은 제 huggingface organization 에 전부 공개해놔서 여기서 다운받아서 사용해보실 수 있습니다. 모델들은 추가적인 사전학습이나 파인튜닝이 진행되면서 계속 업데이트를 할 예정입니다.
이번 논문은 short paper, 그리고 industry쪽에 초점을 맞추는 방향으로 작성을해서 내용이 짧고 가볍습니다. 주식이나 코인쪽에서 다양한 패턴매칭 툴이 존재합니다. 대부분 패턴매칭 툴은 현재 차트 구간이 주어지면 과거 유사한 차트 구간을 포착해서 트레이더에게 보여주는 방식으로 동작합니다. 그럼 트레이더는 해당 과거 유사한 구간을 보고 그 당시에 가격이 어떤식으로 흘러갔는지 참고해서 현재 투자에 있어서 가장 좋은 행동은 무엇일지 결정합니다. 코인쪽에서 이러한 패턴매칭 툴의 예시는 trendspider 아니면 miningcalc.kr 정도가 먼저 생각납니다. 하지만 이러한 대중적으로 공개된 패턴 매칭 지표들은 크게 두가지 한계점이 있다고 생각했습니다. (1) 일차원적으로 차트 데이터만 고려해서 패턴 매칭을 진행합니다. (2) 유사 차트 구간을 추천하고 이후의 행동은 모두 트레이더에게 맡깁니다. 이 두가지 문제점을 address하기 위해서, 저희는 차트 데이터와 텍스트 데이터 (코인니스 뉴스 속보)를 둘 다 활용해서 패턴 매칭을 하는 방법을 제시했고 이러한 유사 차트 구간 정보를 어떻게 모델링에 활용하면 좋을지에 대한 아이디어와 실제로 구현했을때 이러한 방법이 투자에 있어서 도움이 될지를 보여줬습니다. 논문 제목에서 볼 수 있듯이 비트코인 가격에 대한 패턴 매칭을 진행했지만, 여기에서 제시하는 방법론은 적절한 데이터만 구할 수 있다면 다른 종목으로도 충분히 확장이 가능해보입니다.
Contributions
- 차트 데이터와 코인니스 속보 텍스트 데이터를 활용한 멀티모덜 비트코인 가격의 패턴매칭 방법을 제시합니다.
- 멀티모덜 패턴매칭 방법으로 얻은 정보를 비트코인 방향성 예측 모델링에 활용하는 방안을 제시하고, 이 방법이 패턴매칭 정보를 활용하지 않을때보다 더 유용하다는걸 실험적으로 보여줍니다.
비트코인 방향성 분류 프레임워크에 멀티모덜 패턴매칭 정보 사용하기
전체적인 비트코인 방향성 분류 프레임워크는 이전 CBITS와 매우 유사합니다. Ternary classification으로 4시간 단위로 접근하되, 이전 CBITS에서는 뉴스 데이터의 감성 점수를 차트 데이터와 활용했다면, 이번 BIRP는 특정 방식으로 랭크된 과거 차트 구간들의 voting 정보를 피처로 활용합니다 (정확히는 normalize된 voting 정보를 활용합니다). 아래 Figure 1에 전체적인 프레임워크를 묘사했습니다.
| BIRP Architecture |
|---|
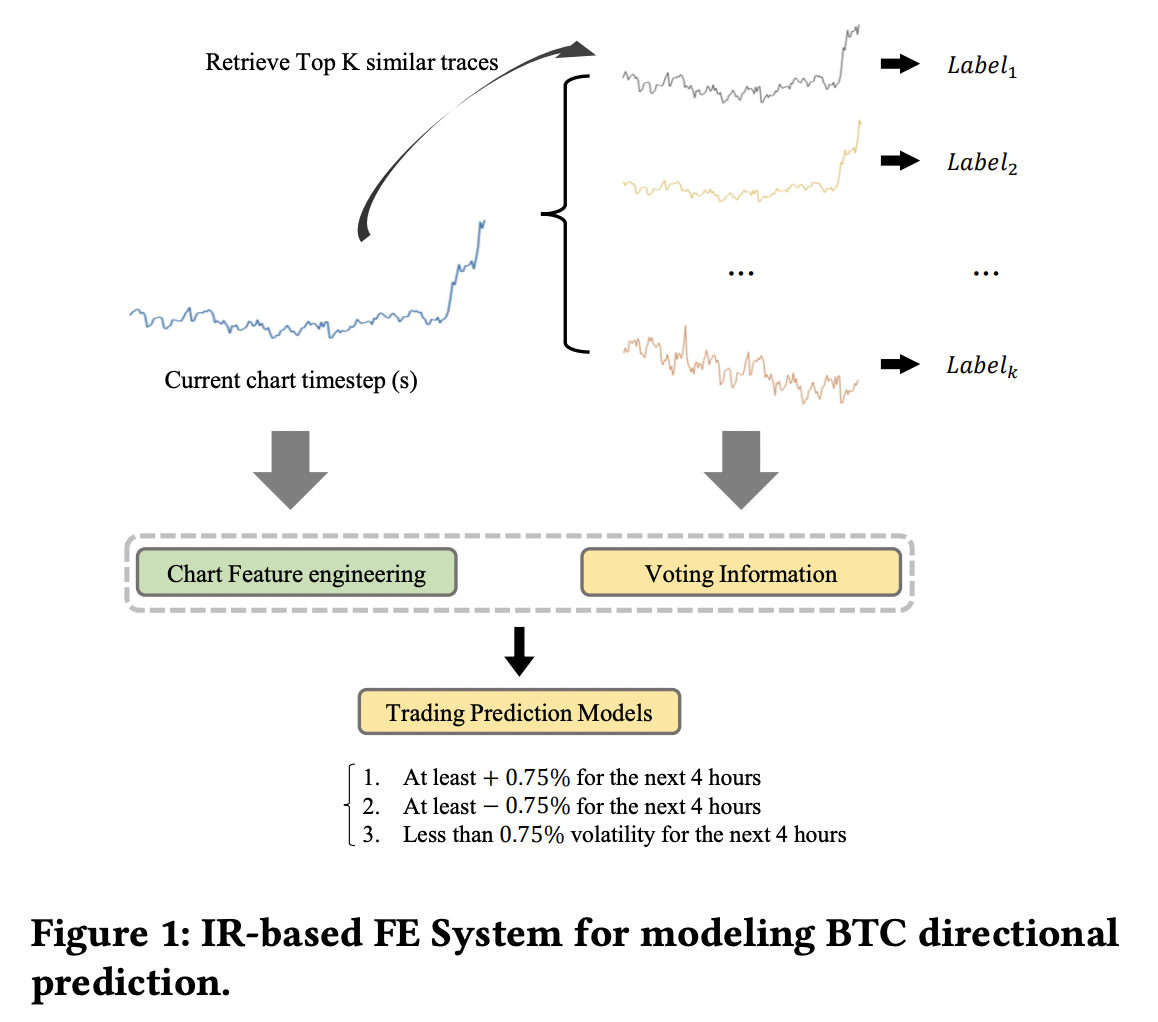 |
저희는 네가지 랭킹 방식을 제시했는데 다음과 같습니다:
- random
- 현재 차트 구간이 주어지면 과거 차트 구간 중 랜덤하게 30개를 샘플해서 가져옵니다.
- euclidean
- 현재 차트 구간이 주어지면 과거 차트 구간 중 현재 차트 구간과의 L2-distance가 가장 가까운 구간 top 30개를 랭크해서 가져옵니다.
- TS2Vec
- 비지도 방식으로 시계열 데이터의 특성들을 학습해서 다양한 downstream task에 대해 효율적으로 임베딩을 뽑는 방식인 TS2Vec 모델을 사용해서 시계열 임베딩을 계산합니다. 현재 차트 구간의 임베딩을 계산하고, 현재 구간의 임베딩과 코사인 거리가 가장 가까운 과거 차트 구간들의 임베딩들 top 30개를 랭크해서 가져옵니다.
- Multimodal
- CryptoRoBERTa를 이용해서 해당 차트 구간동안 나온 모든 뉴스 데이터의 평균 임베딩을 계산하고, 해당 차트 구간의 시계열 데이터의 임베딩을 TS2Vec으로 계산합니다. 이후에 평균 뉴스 임베딩과 시게열 데이터 임베딩의 합해서 멀티모덜 임베딩을 구합니다. 그리고 이러한 멀티모덜 임베딩들의 코사인 유사도가 가장 가까운 순으로 top 30개를 랭크해서 가져옵니다.
- 뉴스 임베딩과 차트 임베딩을 더할때 둘의 차원을 맞추기 위해서 뉴스 임베딩의 차원을 UMAP으로 줄여주는 과정을 거쳤습니다.
실험 데이터
데이터는 이전 CBITS와 비슷하게 바이낸스에서 긁어온 비트코인 차트 데이터와 코인니스에서 얻은 속보형 뉴스 데이터 입니다. 전체 차트와 뉴스 기간은 2017-08-23 16:00:00부터 2023-01-15 20:00:00 까지였고 (11,812개의 데이터 포인트), 차트 데이터는 4시간봉으로 긁어왔습니다. 과거 유사한 구간을 랭킹하는 작업이 필요하기 때문에 풍부한 양의 candidate data가 필요해서 첫 80%의 데이터를 candidate로 나머지 20%의 데이터를 train/validation/test set으로 나눠서 실험을 진행했습니다. train/validation/test set의 기간은 2021-12-18 04:00 부터 2023-01-15 20:00:00까지였고 총 2,363개의 데이터 포인트로 구성이 되어 있었습니다. train/validation/test의 비율은 8:1:1로 진행되었고 각 2,363개의 데이터포인트는 candidate 데이터와 특정 랭킹 방법 (multimodal, euclidean, ts2vec, random)으로 비교되어 해당 데이터포인트와 가장 유사한 30개 데이터포인트들을 미리 계산해뒀습니다.
다른 패턴매칭 방법들과 멀티모덜 패턴매칭 방법의 성능 비교와 Backtest 결과
CBITS와 비슷한 프레임워크와 모델링 방식을 사용했지만 사용하는 모델 자체는 XGBoost하나로만 제한시키고 다양한 랭킹 방법을 비교하는 방식으로 실험을 진행했습니다. 만약 시간적 여유가 더 있었다면, 다른 모델들도 활용해서 여러가지 조합을 실험해 볼 수 있었을 것 같습니다.
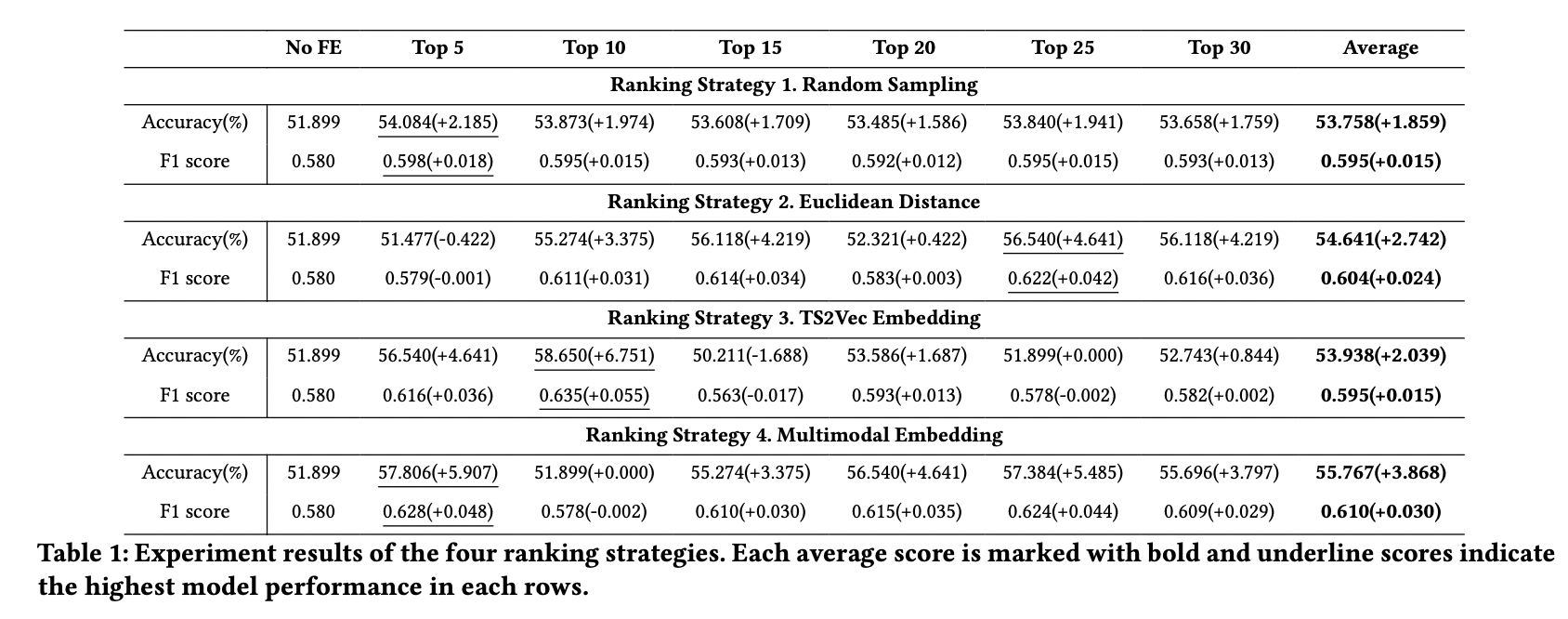
voting 정보를 top 5, 10, 15, 20, 25, 30를 활용하는 방법으로 진행했는데 보다시피 multimodal 방식의 랭킹을 이용해서 voting feature를 사용하는게 이러한 정보를 사용하지 않는것과 비교해서 가장 높은 성능 향상을 보였습니다.
그리고 top 5, 혹은 top 10을 활용하는게 대부분의 경우 결과가 가장 좋아보입니다. 추측이지만 너무 많은 과거 유사 구간들로부터 voting 정보를 계산하면 noise가 데이터에 너무 많이 추가되는 경향이 있는 것 같습니다.
정확도나 F1 수치 자체로만 본다면 아직 개선해야할점이 많지만 유사도 기반 랭킹으로 얻은 voting 정보를 활용하는게 유용하단걸 보여주기에는 충분해 보입니다.
| Backtest 결과 |
|---|
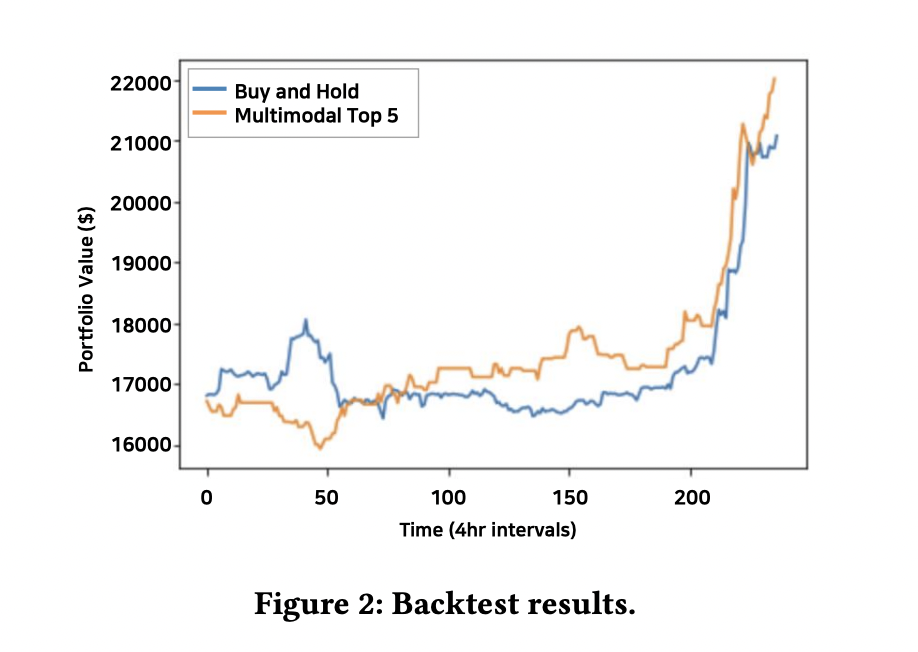 |
multimodal top 5 방식의 랭킹으로 voting 정보를 계산해서 backtest를 진행했을때 test set에서 buy and hold를 이기는 모습을 보여주면서 이 방식을 고도화시키면 수익률이 뛰어난 모델을 만들 수 있을 것 같습니다 (이전 CBITS와는 다르게 논문 제출 당시 아쉽게도 실투 결과를 포함할 시간은 없었습니다).
Conclusion
차트 데이터뿐만 아니라 뉴스 데이터도 활용해서 멀티모덜한 방법으로 유사한 과거 차트 구간을 랭킹하는 방법을 제시했습니다. 차트, 뉴스외에도 더 많은 정보를 포함한 랭킹 방식도 미래에 개발할 수 있을 것 같습니다 (비트코인의 경우 BTC dominance, Dollar index, on chain data같은 정보도 포함해서 유사도 랭킹에 활용). 그리고 이렇게 랭크해서 얻은 과거 유사 차트 구간정보를 활용해서 비트코인 방향성 예측에 도움이 되는 피처로서 활용할 수 있다는것도 실험적으로 보여줬습니다.
트레이딩 봇 뿐만 아니라 이러한 임베딩 정보를 활용한 유사 코인 뉴스 검색기나 패턴 매칭 툴도 만들어서 빠른시일내에 서비스를 진행할 계획도 있습니다. 아래 예시는 유저가 쿼리 뉴스를 입력하면, 해당 쿼리 뉴스와 유사하다고 판단된 과거 뉴스를 랭킹해서 보여주고 해당 뉴스가 나온 시점의 비트코인 차트 움직임도 보여줘서 (30분봉 기준으로) 투자자가 참고할 수 있게 합니다. 이 논문 작업을 진행하면서 매우 다양한 비트코인 투자 지표 아이디어가 떠올라서 이러한 아이디어들들 구현해보고 서비스해보는 목표가 생겼습니다.
| 임베딩을 활용한 랭킹 지표 예시 |
|---|
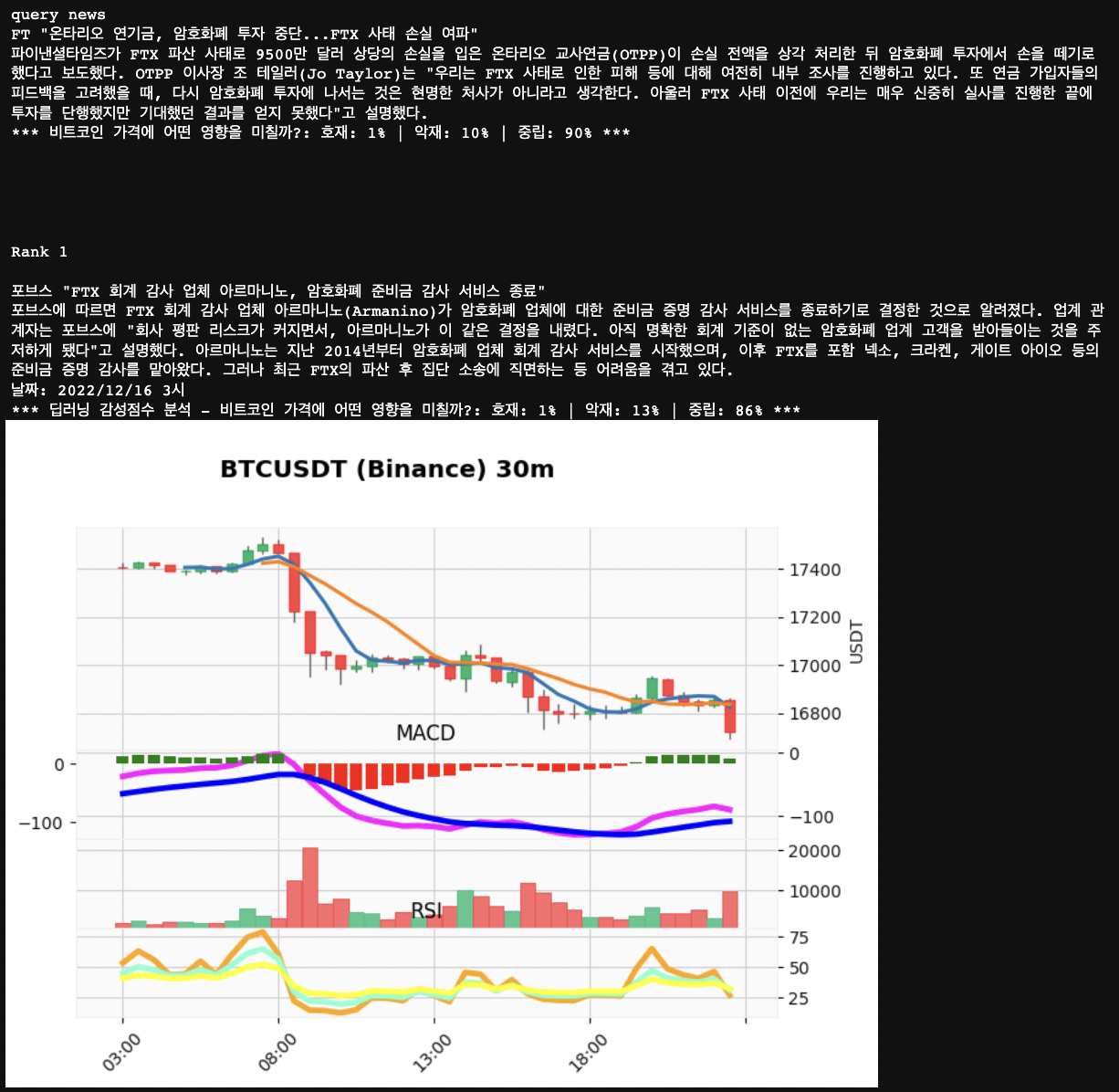 |
트레이딩 관련 논문을 하나 더 준비중인데, 완성이 되면 블로그에 또 업데이트하도록 하겠습니다. 글 읽어주셔서 감사합니다!
References
Tianqi Chen and Carlos Guestrin. 2016. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (San Francisco, California, USA) (KDD ’16). ACM, New York, NY, USA, 785–794. https://doi.org/10.1145/2939672.2939785
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. 2020. A simple framework for contrastive learning of visual representations. In International conference on machine learning. PMLR, 1597–1607.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics, Minneapolis, Minnesota, 4171–4186. https://doi.org/10.18653/v1/N19-1423
Guozhu Dong and Vahid Taslimitehrani. 2016. Pattern-aided regression modeling and prediction model analysis. In 2016 IEEE 32nd International Conference on Data Engineering (ICDE). 1508–1509. https://doi.org/10.1109/ICDE.2016.7498398
Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2021. SimCSE: Simple Contrastive Learning of Sentence Embeddings. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 6894–6910. https://doi.org/10.18653/v1/2021.emnlp-main.552
Xueyuan Gong and Yain-Whar Si. 2013. Comparison of subsequence pattern matching methods for financial time series. In 2013 Ninth International Conference on Computational Intelligence and Security. IEEE, 154–158.
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2021. DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION. In International Conference on Learning Representations. 1–21. https://openreview.net/forum?id=XPZIaotutsD
Gyeongmin Kim, Minsuk Kim, Byungchul Kim, and Heuiseok Lim. 2023. CBITS: Crypto BERT Incorporated Trading System. IEEE Access 11 (2023), 6912–6921. https://doi.org/10.1109/ACCESS.2023.3236032
Leland McInnes, John Healy, and James Melville. 2018. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426 (2018).
Satoshi Nakamoto. 2008. Bitcoin: A peer-to-peer electronic cash system. Decentralized Business Review (2008), 21260.
Marc Velay and Fabrice Daniel. 2018. Stock chart pattern recognition with deep learning. arXiv preprint arXiv:1808.00418 (2018)
Zhihan Yue, Yujing Wang, Juanyong Duan, Tianmeng Yang, Congrui Huang, Yunhai Tong, and Bixiong Xu. 2022. Ts2vec: Towards universal representation of time series. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36. 8980–8987.