
![]()


Kim, Jaehyeon, Jungil Kong, and Juhee Son. "Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech."
International Conference on Machine Learning (ICML) 2021
Variational Inference with adversarial learning for end-to-end Text-to-Speech
안녕하세요! MINDs Lab Brain에서 text-to-speech (TTS) 연구를 하고 있는 정원빈입니다. 오늘은 지난 여름에 발표된 end-to-end TTS인 Variational Inference with adversarial learning for end-to-end Text-to-Speech, VITS에 대해 소개하고, 리뷰를 진행하고자 합니다.
Contributions
- 1단계 합성 및 병렬 트레이닝이 가능하며 성능이 기존 모델에 견줄 수 있는 end-to-end TTS를 제안했습니다.
- Variational Auto-Encoder (VAE)의 구조를 적용하여 2단계 합성을 하나로 연결시켰습니다.
- Variational inference에 normalizing flow와 generative adversarial network (GAN)의 adversarial training을 결합시켜 표현력을 높였습니다.
- Stochastic duration predictor (SDP)를 사용하여 랜덤하게 음성의 길이를 예측하므로 음성의 다양성이 향상되었습니다.
Background Knowledge
Neural TTS의 변화: 2단계에서 1단계로
Neural network를 사용한 TTS 연구가 시작되고, 연구가 축적되면서 그 파이프라인은 2단계 합성이 주류를 차지하게 됩니다.
이러한 2단계 합성 과정은 텍스트를 중간 결과물로 바꾸는 어쿠스틱 모델과 중간 결과물을 음성 파형으로 변환하는 보코더로 이루어지는데, 높은 음질의 음성을 합성하는데 성공했지만 어느 한 단계에서 트레이닝이 직렬로 이뤄지거나 이전 단계에서 얻은 결과물로 이후 단계를 fine-tuning하는 작업이 요구되는 등의 문제점이 남아 있습니다. 또한 중간 결과물의 형태(주로 mel-spectrogram)가 고정되어 hidden representation 학습을 통한 변형이나 성능 향상이 불가능하다는 난점이 존재합니다.
최근 이런 난관을 극복하기 위해 FastSpeech 2S[5]나 EATS[6] 같이 텍스트에서 음성을 바로 합성하는 end-to-end TTS들이 제안되고 있는데, 이들은 adversarial training에 전체 음성 대신 짧은 오디오 클립을 사용하고 길이가 다른 음성 사이의 차이를 loss로 계산하기 위한 방식을 고안하였습니다. 그럼에도 불구하고 1단계 합성을 통해 만들어진 음성의 음질은 2단계 합성의 그것보다 낮은 수준에 머물렀습니다.
오늘 리뷰의 주인공인 VITS 또한 1단계 합성이 가능한 end-to-end TTS 연구 중 하나로, 어떤 방식을 통해 VITS가 2단계 합성만큼 높은 음질을 달성했는지 설명하도록 하겠습니다.
TTS의 근본적 난제: One-to-Many Problem
사람들은 같은 텍스트도 여러 방식으로 읽을 수 있습니다. 사람마다 다른 목소리와 발화 패턴을 가지는 건 물론이고, 같은 사람이라도 높낮이나 속도를 조절하면서 같은 글자를 다르게 읽을 수 있기 때문에 텍스트와 음성을 one-to-many relationship를 이루게 됩니다. 이런 인간 발화의 특성 때문에 TTS 또한 일종의 one-to-many problem이 되고, 때문에 하나의 텍스트에 하나의 음성만이 대응된다는 가정 하에서 이 문제를 해결하려 하는 것은 위험한 시도가 됩니다.
VITS 또한 이러한 TTS의 특성을 인식하고, latent modeling과 SDP를 통해 이에 대응하고자 합니다.
합성음의 길이 예측: Alignment와 Duration Predictor-based Model
2단계 합성 중 어쿠스틱 모델은 보통 인코더가 텍스트를 입력받고, 디코더가 음성을 출력하는 형태로 구성됩니다. 그러나 입출력이 다른 길이의 시퀀스이므로, 출력 시퀀스의 특정 부분이 입력 시퀀스의 어떤 부분에 대응되는지 알아야 길이를 맞춰가며 결과물을 생성할 수 있습니다. 이러한 입출력 사이의 관계를 alignment라고 부릅니다. 사람은 텍스트를 적힌 순서대로 읽어나가므로, 달리 보면 alignment는 텍스트의 각 부분이 음성에서 얼마만큼의 길이(duration)를 차지하는지 나타낸다고 볼 수 있습니다.
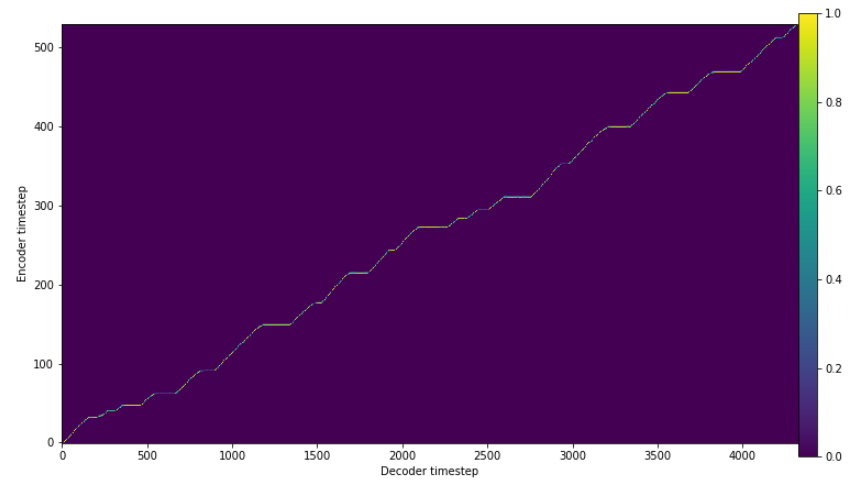
따라서 텍스트만 주어지는 상황에서 TTS는 alignment를 구하기 위해 텍스트의 각 음소(phoneme)가 음성에서 얼마나 길게 발화되는지 예측할 필요가 있습니다. Duration predictor는 이에 대한 해법 중 하나로, 텍스트 내의 각 음소의 길이를 예측해서 alignment를 계산합니다.
가역변환으로 복잡한 분포를 다루기 쉽게 바꾸기: Normalizing Flow
Normalizing flow는 GAN이나 VAE와 같은 일종의 생성 모델입니다. 가우시안 분포 같은 단순한 분포에 일련의 가역 변환을 연쇄적으로 가하여 복잡한 분포로 변형시키는 과정을 통해 현실의 복잡한 분포를 간단한 분포에 대응시킬 수 있습니다. 따라서 약간의 계산 과정을 거치면, 현실의 확률 분포에 기반한 를 단순한 분포에서 발생한 latent 로부터 구할 수 있다는 점이 normalizing flow의 특징이며, 일련의 가역 변환으로 구성되기 때문에 반대로 에서 를 구할 수도 있습니다.
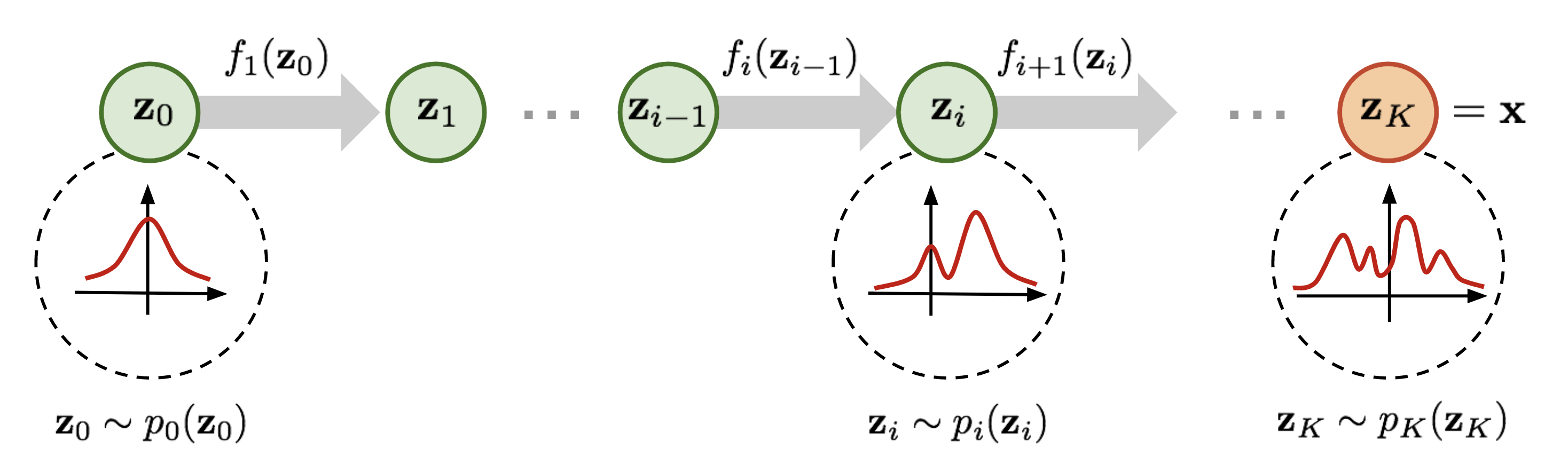
VITS에서 normalizing flow는 주로 모델을 훈련하는 중에 복잡한 데이터 분포에서 추출된 값을 정규 분포 하의 값으로 변환하여 관계를 학습하고, 음성 합성 시에는 정규 분포에서 샘플링된 값이나 노이즈를 그에 대응하는 복잡한 분포의 값들로 역변환하는 방식으로 사용됩니다.
Overview
이 섹션에서는, VITS의 구조에 의해 loss 식이 계산되는 과정을 다룹니다. VITS의 도식도는 아래와 같이 나타납니다.
| VITS at training | VITS at inference |
|---|---|
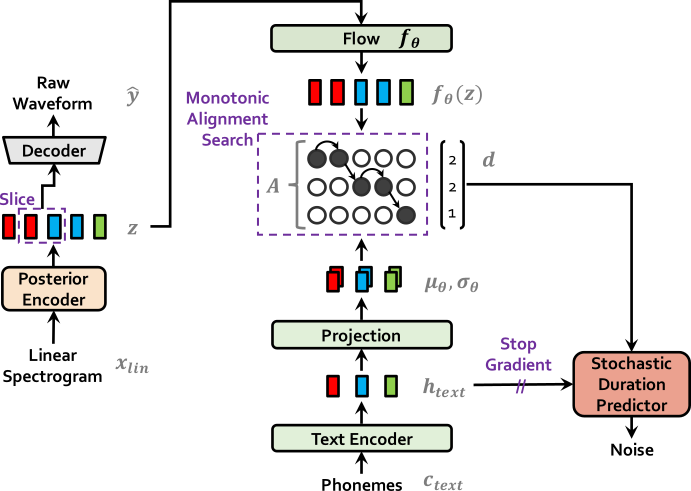 | 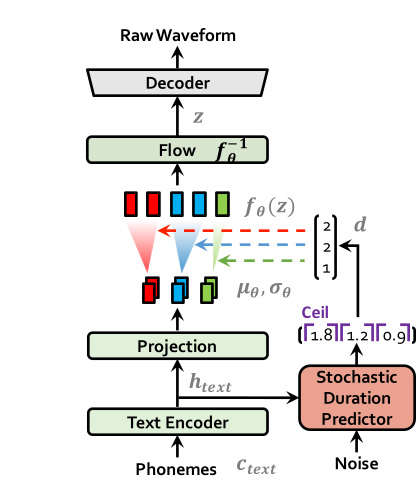 |
전체적으로 보면, VITS는 text encoder와 flow로 이뤄진 prior encoder, 그리고 latent 를 음성으로 변환하는 decoder로 이뤄진 VAE의 구조를 취하고 있습니다. 거기에 duration predictor, posterior encoder, discriminator, monotonic alignment search (MAS) 등의 모듈 및 과정이 붙은 형태입니다.
따라서 우선 data 의 marginal log-likelihood 하한에 대응되는 evidence lower bound (ELBO)는 아래와 같이 표현할 수 있고, 실제로는 negative ELBO를 training loss로 사용합니다.
Negative ELBO의 두 항은 각각 reconstruction loss와 KL divergence에 해당되고, 풀어서 계산하면 아래와 같이 정리할 수 있습니다. Prior encoder의 경우 latent 를 구하기 위해 text encoder와 alignment 작업을 거치고 다시 flow를 지나기 때문에 추가 항이 붙는 것을 볼 수 있습니다.
또한 decoder는 GAN의 generator에 해당되므로, generator와 discriminator의 loss를 GAN의 adversarial loss에 맞게 설정합니다. 이 때, 추가로 feature matching loss를 설정하여 discrminator의 각 레이어에서 원본 음성과 생성된 음성 feature map 사이의 L1-norm에 기반한 loss를 도입하였습니다.
Duration predictor에서는 입력되는 텍스트의 hidden representation의 각 토큰에 해당되는 latent variable 갯수를 토큰의 길이, 즉 duration으로 고려하여 계산합니다. Glow-TTS는 각 토큰의 예측된 길이를 사용해 MSE loss를 duration loss로 사용하지만, 이는 deterministic duration predictor로 VITS의 SDP처럼 매번 달라지는 발화 길이를 구현하기 위해선 다른 방식이 필요합니다.
그렇게 고안된 SDP는 flow-based model로 duration의 distribution을 모델링하여 maximum likelihood estimation로 duration을 예측합니다. 그러나 여기는 여기는 몇 가지 난점이 있는데 우선 duration은 불연속적인 양의 정수지만 continuous normalizing flow에서는 연속적인 값을 다룬다는 것이고, 또 duration은 스칼라이기 때문에 flow의 가역 조건을 충족하기 위한 high-dimension transformation이 어렵습니다. 이를 위해 해결책으로 도입된 것이 variational dequantization과 variational data augmentation입니다.
세부적으로 설명하면, duration sequence d와 같은 차원의 random variable 와 를 생성합니다. 이때 의 범위는 로 잡아 가 양의 실수가 되게 설정하고, 와 를 channel-wise하게 concatenate하여 higher dimensional latent representation을 만듭니다. 이 값은 flow을 통과해 로 변환됩니다. 여기서 쓰인 random variable 를 모두 를 조건으로 한 approximate posterior distribution 에서 샘플링되므로, duration loss는 duration log-likelihood의 negative ELBO가 됩니다. 샘플링 과정에서는 반대로, random noise가 flow의 역변환을 거쳐 duration이 예측되고, ceil operation을 거쳐 정수 형태로 변환됩니다.
고로 loss의 최종 형태는 아래와 같이 되고, discrminator는 별개로 를 사용합니다.
Alignment Estimation
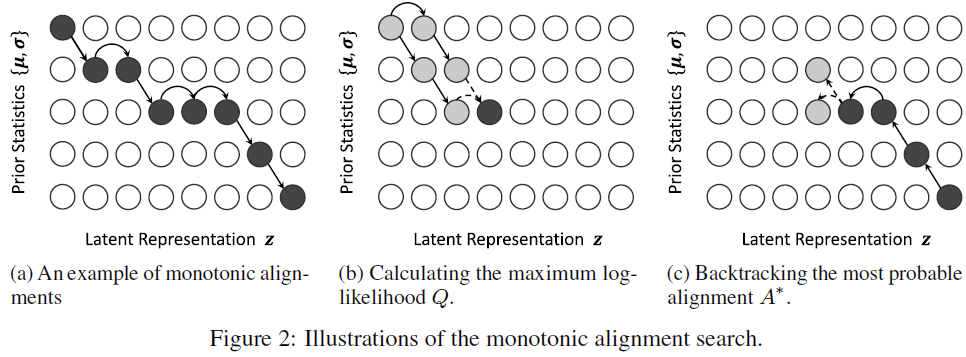
VITS는 서로 다른 길이의 시퀀스인 hidden representation과 latent variable 사이의 alignment를 구하기 위해 Glow-TTS의 monotonic alignment search를 활용합니다. MAS는 dynamic programming을 사용한 탐색법입니다. 탐색의 과정은 모든 양쪽의 요소들이 누락되지 않게 alignment에 대응되고(non-skipping), 선후관계가 뒤집히지 않도록, 즉 앞의 latent variable가 뒤의 latent variable에 해당되는 hidden representation보다 더 뒤쪽의 hidden representation에 해당하지 않도록(monotonic) 역방향으로 진행됩니다.
최적의 alignment 는 flow 를 통과한 의 likelihood를 최대화하므로, 는 아래와 같이 추산됩니다.
다만 VITS는 VAE 기반이므로 이 조건을 그대로 적용하기 어려우므로, 대신 loss의 ELBO를 최대화하는 를 찾는 식으로 재정의하였습니다.
MAS를 사용하는 데는 몇가지 이점이 따르는데, 우선 발화의 특징에 부합하는 non-skipping monotonic alignment를 확정적으로 얻을 수 있고, 외부 aligner를 사용하지 않고 end-to-end로 모델을 디자인할 수 있습니다.
Architecture
VITS는 prior encoder, posterior encoder, decoder, discriminator, SDP의 5가지 모듈로 구성되어 있습니다. 차례대로 각 모듈의 구현에 대해 설명하도록 하겠습니다.
Prior Encoder
Prior encoder는 텍스트를 hidden representation으로 변환하는 text encoder와 latent variable을 양방향 변환하는 normalizing flow 단계로 이루어져 있습니다.
Text Encoder
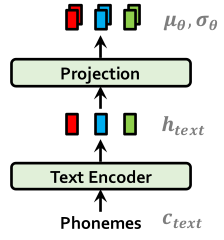
Text encoder는 transformer 기반으로, absolute positional encoding 대신 relative positional representation을 사용합니다. Text encoder에서 출력된 hidden representation 은 linear projection을 거쳐 prior distribution을 구성하기 위한 mean 및 variance 로 변환됩니다.
Normalizing Flow
Normalizing flow는 가역 구조를 가진 affine coupling layer의 stack으로, 각 레이어는 WaveNet residual block으로 이뤄져 있습니다. 계산의 편리함과 단순성을 위해 volume-preserving transformation 조건을 걸어 Jacobian determinant을 1로 유지하는 제한을 걸었습니다.
Training 중에는 latent variable 가 정방향으로 변환되어 가 되고, inference 중에는 반대로 가 역방향 변환을 거쳐 latent variable z을 계산합니다.
Monotonic Alignment Search
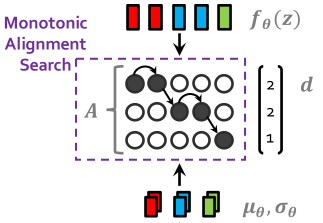
Flow를 거쳐 변환된 latent variable 와 text hidden representation에서 생성된 mean 및 variance 배열 사이의 alignment와 duration이 MAS를 통해 구해집니다. Text hidden representation의 길이를 latent variable에 맞춰주기 위해 duration만큼 mean과 variance의 각 요소를 반복해 연장시키고, KL divergence 계산에 확장된 값과 latent variable을 사용하여 양측의 분포를 맞춰줍니다.
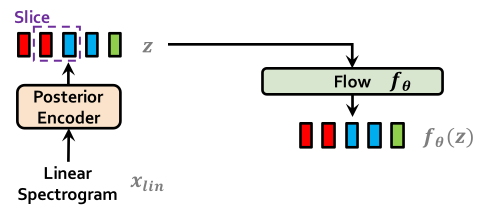
Posterior Encoder
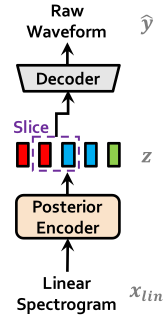
Posterior encoder는 음성의 linear spectrogram에서 latent variable을 추출하며, WaveGlow[2]의 non-causal WaveNet residual block을 사용했습니다. 각 블록은 gated activation unit이 붙은 dilated convolution과 skip connection으로 이뤄져 있습니다. 마지막 단의 linear projection에서 normal posterior distribution의 mean과 variance를 출력하고, 이걸로 샘플링한 가 latent variable의 역할을 합니다.
Decoder
Decoder는 latent varable을 raw waveform으로 바꿔주는 역할을 하며, HiFi-GAN[3] V1 generator를 기반으로 하고 있습니다. 따라서 transposed convolution가 stack되어 있으며 각 convolution 뒤에는 multi-receptive field fusion module (MRF)가 붙어있어, 각각 다른 receptive field size를 가진 residual block을 거쳐 최대한 많은 수의 패턴을 고려하여 음성을 합성합니다. 다만 마지막 레이어에서 bias parameter를 제거했는데, audio mean은 보통 0이므로 이는 불안정한 gradient scaling을 유발하기 때문입니다.
Training 중에는 decoder에 latent variable 전체가 아니라 특정 길이로 랜덤하게 잘린 부분을 넣고, 선택된 부분에 대응되는 ground-truth의 일부분을 가져다 타겟으로 사용하여 reconstruction loss를 계산했습니다. Inference 중에는 그냥 latent variable 전체를 사용합니다.
Discriminator
Discriminator도 decoder와 같이 HiFi-GAN의 multi-period discriminator를 쓰는데, 효율을 위해 다소 간소화된 버전입니다. 이 모듈은 여러 개의 sub-discriminator로 이루어져 있어, waveform의 서로 다른 주기적 패턴을 포착합니다.
Stochastic Duration Predictor
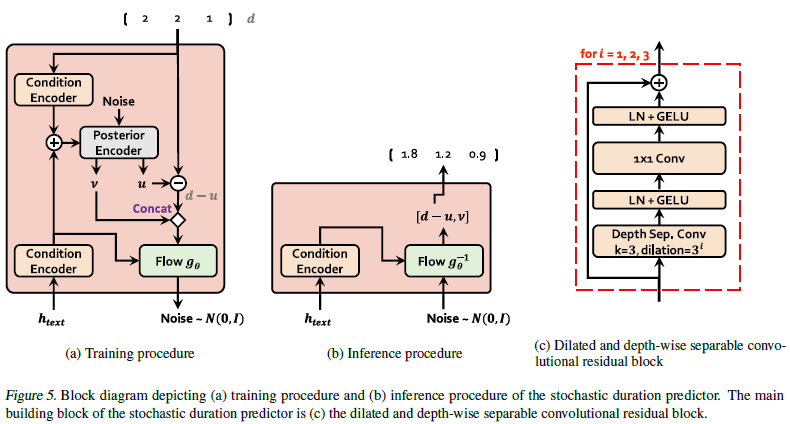
SDP는 text hidden representation으로부터 stochastic하게 duration을 예측하는 모듈로, 유동적인 발화 속도라는 인간 발화의 특징을 반영하기 위한 접근입니다. 앞서 설명한 것과 같이 flow 기반의 모델로 구성되며 text hidden representation과 duration을 처리하는 condition encoder, 이 두 조건을 사용해 noise에서 random variable을 생성하는 flow-based posterior encoder, 그리고 noise와 duration을 가역변환시키는 normalizing flow 로 이루어져 있습니다.
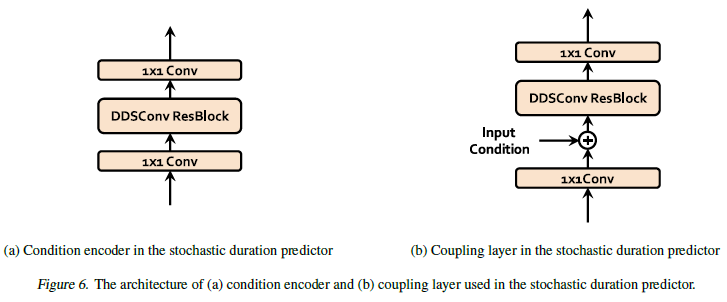
Conditional encoder와 flow-based network 내의 coupling layer에서 dilated and depth-separable convolutional (DDSConv) layer가 사용되는데, DDSConv를 사용한 이유는 넓은 receptive field를 유지하면서 parameter efficiency를 높이기 위함입니다. Flow-based network인 Posterior encoder와 normalizing flow가 모두 neural spline flow를 사용하는데, 일반적으로 flow 구현에 쓰이는 affine coupling layer보다 표현력 측면에서 효과가 좋았기 때문입니다.
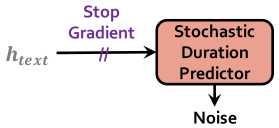
더하여 SDP에 stop gradient operator를 적용하여 입력 조건을 통해 다른 모듈에 영향 미치지 못하도록 제한합니다.
이렇게 구성된 SDP는 training 시에는 alignment에서 구한 duration을 가지고 학습되고, inference 중에는 텍스트를 통해 예측한 값을 duration으로 사용합니다.
Speaker Embedding
여러 화자의 데이터에 대해 학습할 경우, 모델이 각 화자의 특징을 반영할 수 있도록 화자별로 임베딩을 만들어 입력에 더해주는 방식을 사용합니다. 화자의 정보가 제공되는 모듈은 prior encoder의 normalizing flow, posterior encoder, decoder, SDP이며, text encoder에는 제공되지 않습니다.
Results
Experiment Setup
저자들은 VITS의 성능을 비교할 대조군으로 autoregressive model인 Tacotron 2와 non-autoregressive model인 Glow-TTS를 선택했습니다. 둘 다 보코더로는 HiFi-GAN을 사용합니다. 데이터셋은 단일 화자 환경에선 LJSpeech를, 다화자 환경에서는 VCTK를 사용했습니다.
생성된 합성음 샘플들은 인간 평가자가 음성을 듣고 음질에 대해 1~5점 사이의 점수를 매기는 mean opinion score (MOS) 방식으로 평가됩니다.
Speech Quality
본 섹션에서는 VITS가 합성한 음성이 실제 음성에 얼마나 근접한지, 인간이 듣기에 얼마나 자연스러운지에 대해 다룹니다.
Single Speaker Setting
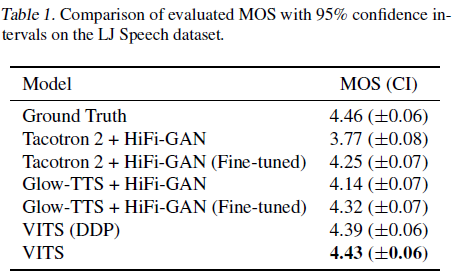
기존의 2단계 합성 방식을 사용하는 모델들과 비교한 결과, fine-tuning한 경우보다도 VITS의 음질이 높았고 ground-truth인 원본 음성에도 매우 근접한 점수를 받았습니다. 더하여 SDP를 deterministic duration predictor (DDP)로 대체해 음성 길이를 고정시킨 경우도 상당히 높은 점수를 기록했습니다. 이를 통해 SDP가 음질 향상에 기여한다는 점과 VITS는 DDP를 사용해도 기존 모델들과 비교할 만한 성능을 낸다는 점을 확인할 수 있습니다.
Ablation
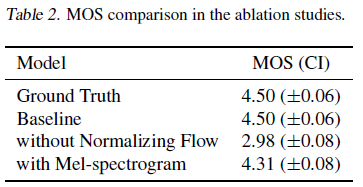
VITS의 여러 요소가 얼마나 중요한지 그 영향력을 확인하기 위해, 각 부분을 제외하고 평가하는 ablation study를 진행했습니다. 그 결과, prior encoder의 normalizing flow를 제거한 경우 상당한 성능 저하가 있었고, posterior encoder의 입력은 linear-scale이 아닌 mel-scale spectrogram으로 바꿨을 때도 약간의 성능 저하가 관찰되었습니다.
Multi-Speakers Setting
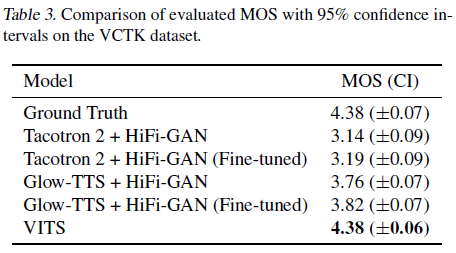
화자별도 임베딩을 할당해 다화자 데이터로 학습한 경우, 마찬가지로 VITS가 타 모델보다 높은 음질을 보였습니다. VITS가 다화자 환경에서도 사용 가능함을 확인시켜주는 결과입니다.
Speech Variation
본 섹션에서는 VITS가 얼마나 다양한 특성의 음성을 합성할 수 있는지, 합성한 음성이 인간 발화의 특성을 얼마나 잘 반영하는지에 대해 다룹니다.
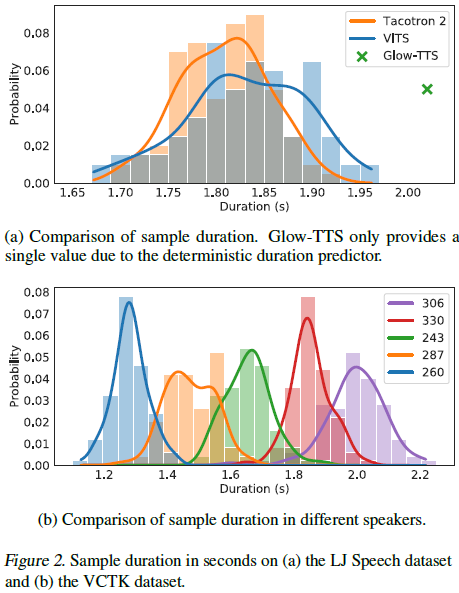
Fig. 2(a)는 Tacotron 2, Glow-TTS, VITS가 "How much variation is there?"라는 문장에 대해 생성한 합성음 100개의 길이에 대해 분포를 나타낸 것입니다. Glow-TTS는 DDP를 사용해 고정된 길이의 문장만 내놓는 반면 VITS는 Tacotron 2와 비슷한 분포를 따르는데, 같은 문장에 대해서도 다양한 길이로 다르게 발화하는 것을 알 수 있습니다.
Fig. 2(b)는 VITS가 생성한 100개 발화의 길이에 대해 분포를 화자별로 나타낸 것으로, 각 화자의 특성에 따라 발화 길이가 크게 달라지므로 VITS가 화자의 특성에 기반하여 발화 길이를 예측함을 확인할 수 있습니다.
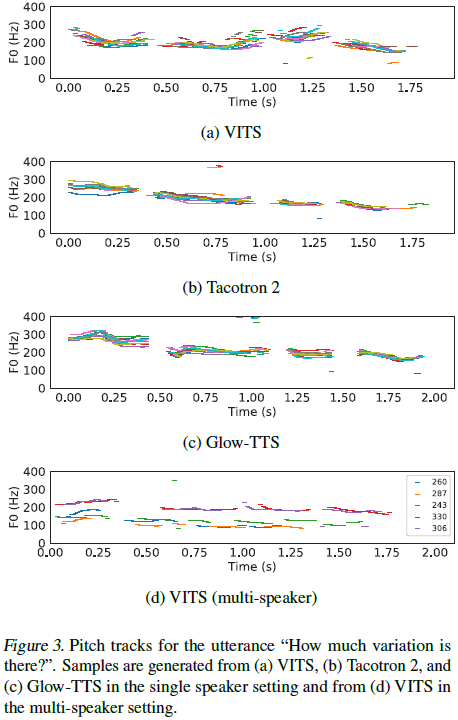
Fig. 3(a), (b), (c)는 각 모델이 생성한 발화 10개의 F0 contour를 나타낸 것으로 VITS가 합성한 음성이 다양한 리듬과 높낮이를 가짐을 확인할 수 있고, Fig. 3d에서는 더 나아가 각 화자별로 다른 발화의 리듬을 잘 표현함을 알 수 있습니다.
Synthesis Speed

100개의 발화를 합성할 때 각 모델의 평균 합성 속도를 나타낸 것으로, SDP를 빼면 더 빨라지지만, SDP를 사용해도 기존의 Glow-TTS보다 빠름을 알 수 있습니다. 저자들은 이러한 결과에 대해 VITS는 mel-spectrogram 같은 고정된 형식의 중간 단계 결과물을 생성할 필요가 없으므로 샘플링 효율이 크게 상승하였다고 분석했습니다.
Voice Conversion
앞서 언급한 바와 같이 다화자 환경에서 text encoder에는 화자 임베딩이 입력되지 않으므로 latent variable은 화자에 무관한 값이 됩니다. 따라서 이러한 speaker-independent representation에 화자 정보를 조건으로 제공하여 음성을 합성한다면, 특정 화자의 발화를 다른 화자가 발화한 것처럼 바꾸는 voice conversion (VC)이 가능합니다.
원래 화자인 s에 대해 바꾸고 싶은 발화의 linear spectrogram 을 가지고 posterior encoder에 입력시키고, 여기서 나온 latent variable을 normalizing flow를 거쳐 변환시켜 speaker-independent representation 으로 바꿉니다.
이렇게 만들어진 independent representation인 e에 대해 다른 새로운 화자 을 조건으로 걸고 normalizing flow의 역변환과 decoder를 거쳐 음성을 합성하면, 다른 조건들은 유지한 채 화자의 특성만 대체된 새 음성 을 얻을 수 있습니다.
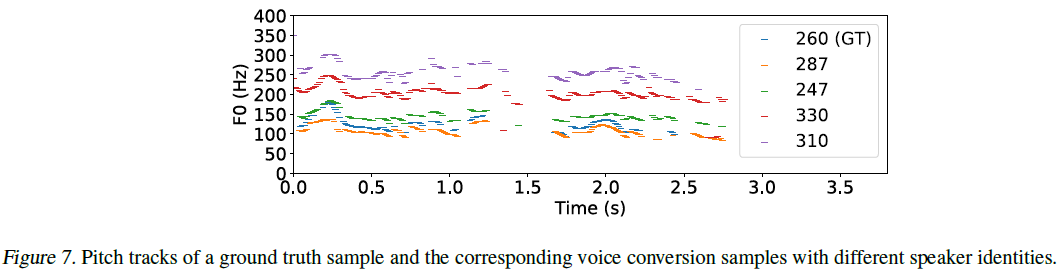
즉 기본 음성을 posterior encoder와 normalizing flow의 정변환을 거쳐 화자 정보를 제거하고 다시 normalizing flow의 역변환과 decoder를 거쳐 새로운 화자 정보를 넣어 대체해주는 과정으로 볼 수 있습니다. Independent representation을 학습하여 VC에 사용하는 방식은 이전에 Glow-TTS에서 제안된 바 있습니다. 다만 VITS는 1단계 합성이 가능하므로 mel-spectrogram이 아니라 raw waveform의 형태로 변환시킨다는 점이 다릅니다. 한 음성에 대해 여러 음성으로 변환시킨 결과는 아래와 같은데, 전반적으로 음성의 높낮이 추이가 유지됨을 보여줍니다.
Conclusion
이렇게 end-to-end TTS인 Variational Inference with adversarial learning for end-to-end Text-to-Speech, VITS에 대하여 작동 원리와 구조 그리고 성능에 대해 살펴보았습니다. VITS는 사실 상당히 복잡한 모델입니다. VAE, normalizing flow, GAN과 같은 생성 모델의 요소를 모두 포함하고 있고, Glow-TTS나 HiFi-GAN 같이 모델의 기반이 되는 기존 연구에서 차용해온 부분도 많습니다. 여기까지 읽으시느라 수고 많으셨습니다.
VITS 연구가 가진 가장 큰 의의는 1단계 합성 모델로써는 최초로 어쿠스틱 모델과 보코더로 구성된 2단계 합성과 견줄만한 성능의 end-to-end TTS를 제안했다는 점입니다. 이로 인해 학습 과정이 간단해졌고 속도 또한 빨라졌습니다. 더하여 외부 aligner를 사용하지 않아 학습 과정이 더욱 단순화되었고, duration predictor를 통해 음성 발화 속도를 조절할 수 있다는 점도 작지 않은 이점입니다. TTS 연구의 방향은 단순 음질 향상뿐만 아니라 속도 향상, 리듬 조절, 소량의 데이터에 대한 적응, 다화자 설정, 구조 개선(1단계 합성 및 모델 규모 절감) 등 다양한 방면에서 이루어지고 있는데, VITS는 여러 측면에서 성과를 이루었다는 점에서 괄목할 만한 연구라고 생각합니다. 모델링 차원에서 보면, 1단계 합성이 가능한 단일한 모델 내에서 latent variable을 모델링함으로써 voice conversion과 같은 부가 기능 또한 추가할 수 있었습니다.
복잡다단한 모델인 VITS의 흥미로운 면모를 보여드리고 싶어 부족하나마 첫 리뷰를 진행해보았습니다. 다음 리뷰도 기대해주세요!
References
- Kim, Jaehyeon, et al. "Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search" arXiv preprint arXiv:2005.11129 (2020). [arxiv]
- Prenger, Ryan, Rafael Valle, and Bryan Catanzaro. "WaveGlow: A Flow-based Generative Network for Speech Synthesis." ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019. [arxiv]
- Kong, Jungil, Jaehyeon Kim, and Jaekyoung Bae. "HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis." arXiv preprint arXiv:2010.05646 (2020). [arxiv]
- Lilian Weng, Flow-based Deep Generative Models. [blog]
- Ren, Yi, et al. "Fastspeech 2: Fast and high-quality end-to-end text to speech." arXiv preprint arXiv:2006.04558 (2020). [arxiv]
- Donahue, Jeff, et al. "End-to-end adversarial text-to-speech." arXiv preprint arXiv:2006.03575 (2020). [arxiv]