

![]()

A Diffusion Probabilistic Model for Neural Audio Upsampling
안녕하세요 MINDs Lab Brain에서 Audio와 Speech 연구를 하고 있는 이준혁입니다. Audio domain의 딥러닝 연구는 대부분 Sampling Rate 16kHz인 경우에 대해서 진행되었습니다. 생성모델 (TTS) 같은 경우 22.05kHz인 경우도 있었지만 음악이나 영화 쪽에서 많이 쓰이는 44.1kHz나 48kHz에 비해서는 절반밖에 안 되는 sampling rate이었기 때문에 high sampling rate TTS에 대한 수요가 꾸준히 있었습니다. 저희가 개발한 TTS에 대해서 더 높은 퀄리티로 서비스를 제공하기 위해서 Neural Audio Upsampling에 대한 연구를 진행하게 되었습니다. 48kHz라는 높은 sampling rate를 목표로 하는 연구를 진행하다 보니 자연스럽게 최근에 핫한 생성모델인 diffusion model을 적용하게 되었고 최초로 48kHz를 target으로 upsampling 하는데 성공하였습니다. 이렇게 진행한 연구로 승우님과 같이 쓴 paper가 세계 최고의 음성신호처리학회인 INTERSPEECH 2021에 Accept🎉 되어 소개해 드리고자 합니다!
Audio Upsampling
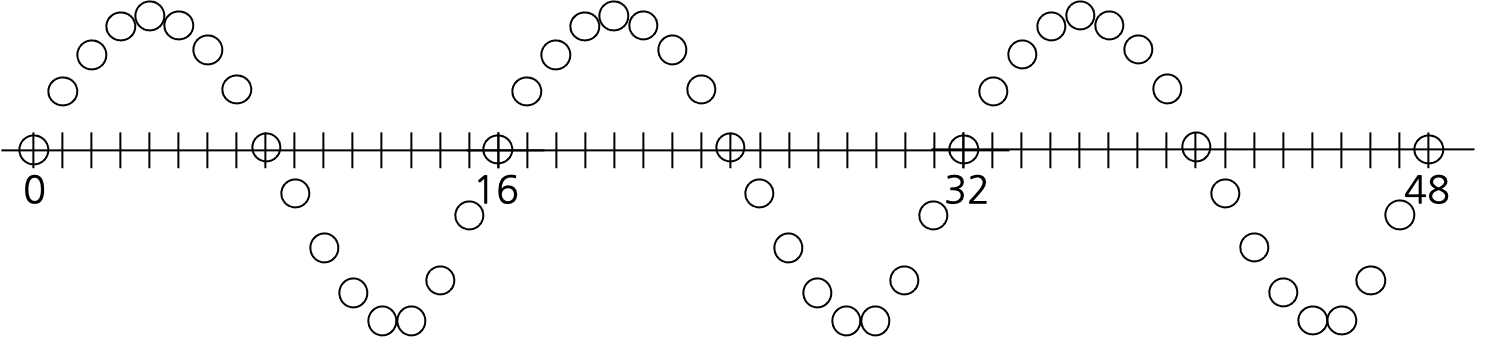
Image domain에서의 super resolution에 해당하는 분야가 Audio Upsampling입니다. Image super resolution에서 따와서 audio super resolution 혹은 주파수 범위 (bandwidth)를 넓힌다는 의미로 bandwidth extension이라고 부르기도 합니다. Audio의 경우 1초에 몇 번 sampling을 하는지를 나타내는 Sampling Rate로 temporal resolution을 표현합니다. 이 값이 중요한 이유는 sampling rate가 정해지면 discrete-time (or digital) audio data가 가질 수 있는 maximum frequency (Nyquist frequency)가 정해지기 때문인데요. Audio domain에 익숙하지 않으신 경우 아래 그림을 보시면 이해가 빠르실 것 같습니다.
- continuous-time 데이터

- 1000Hz로 샘플링 했을 때
- 100Hz로 샘플링 했을 때

공기의 진동에 해당하는 소리를 audio data로 컴퓨터에서 다루기 위해서는 마이크에서 수음된 신호를 discretize하는 과정이 필요한데, 시간에 대해 discretize 하는 것을 sampling이라고 합니다. 원본 신호보다 sampling rate가 상당히 높을 경우 두 번째 그림처럼 신호에 대한 정보를 잘 담을 수 있습니다. 하지만 이 과정에서 신호의 주파수가 N일 때 sampling rate가 2*N 보다 작다면 신호에 대한 어떤 정보도 얻을 수 없는 노이즈가 되게 됩니다. 위의 사진에서 세 번째 그림이 그 케이스죠. 2*N인 경우 운이 좋다면 주파수 N으로 진동하는 신호가 있다 정도는 알아낼 수 있게 됩니다.
어떤 신호를 딥러닝 없이 linear, nearest interpolation 등의 방법으로 upsampling하게되면 위의 이유 때문에 원본의 sampling rate의 절반 이상에 해당하는 주파수는 포함하지 않게 됩니다 정확히는 spectral alias가 생기기 때문에 post filtering을 하기 때문이지만 신호처리 시간이 아니니 넘어가죠. 그래서 sampling rate 자체는 높아지지만 STFT (Short-Time Fourier Transform)을 했을 때 윗부분이 비어 보이게 됩니다. 이런 문제를 해결하기 위해서 딥러닝을 적용한 연구들이 있습니다. 크게 저희 연구와 비교한 케이스 두 개만 소개하고 넘어가겠습니다.
Audio Super Resolution Using Neural Networks[1]
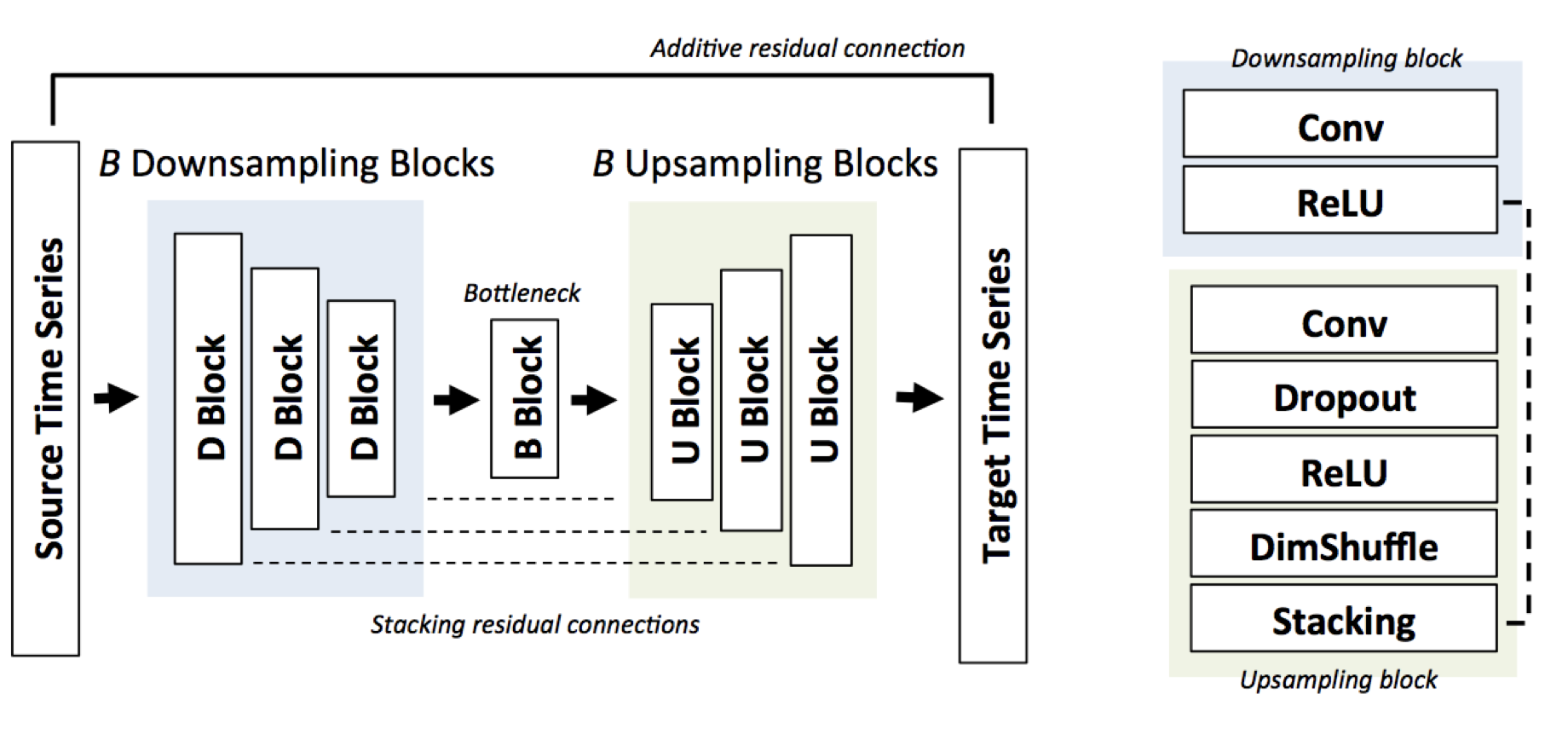
Audio upsampling task에서 딥러닝을 적용한 첫 논문입니다. U-Net과 같은 구조를 적용하였고 N Hz 신호를 input으로 하고 N*r Hz 신호를 output으로 하는 모델입니다. Loss로 L2-norm을 사용하였습니다.
Bandwidth Extension on Raw Audio via Generative Adversarial Networks[2]
GAN을 사용해서 upsampling을 시도한 논문입니다. 구조 자체는 위의 논문과 비슷하고 loss로 L2-norm, discriminator loss, feature loss를 사용하였습니다.
Diffusion Probabilistic Models
What is Diffusion Model?
최근 Denoising Diffusion Probabilistic Model[3]을 필두로 diffusion probabilistic model (줄여서 diffusion model)이 핫한 생성모델로 떠오르고 있습니다. 더 넓은 범위의 score-based model이라는 것도 있으나 이 친구는 아마 다른 포스트로 소개할 것 같습니다. Diffusion model은 GAN이나 VAE와 다르게 output과 latent variable의 사이즈가 같습니다. latent varable은 각 step 마다 원본에 일정한 Gaussian noise가 더해진 것으로 정의됩니다. 이를 0부터 T까지의 step을 가지고 forward/reverse 두 개의 path를 가지는 Markov chain으로 생각합니다. Forward path의 경우 위에서 설명한대로 그 전 step에 Gaussian noise를 더하는 것으로 정의되고 reverse path 의 경우 forward path에서 더해진 Gaussian noise를 예측해서 빼는 것으로 정의됩니다. 결과적으로 Gaussian distribution으로부터 sampling한 latent variable을 여러 번 iteration을 하는 Markov Chain Monte-Carlo Sampling을 통해 noise를 제거해가면서 우리가 원하는 output으로 sampling하는 모델입니다.
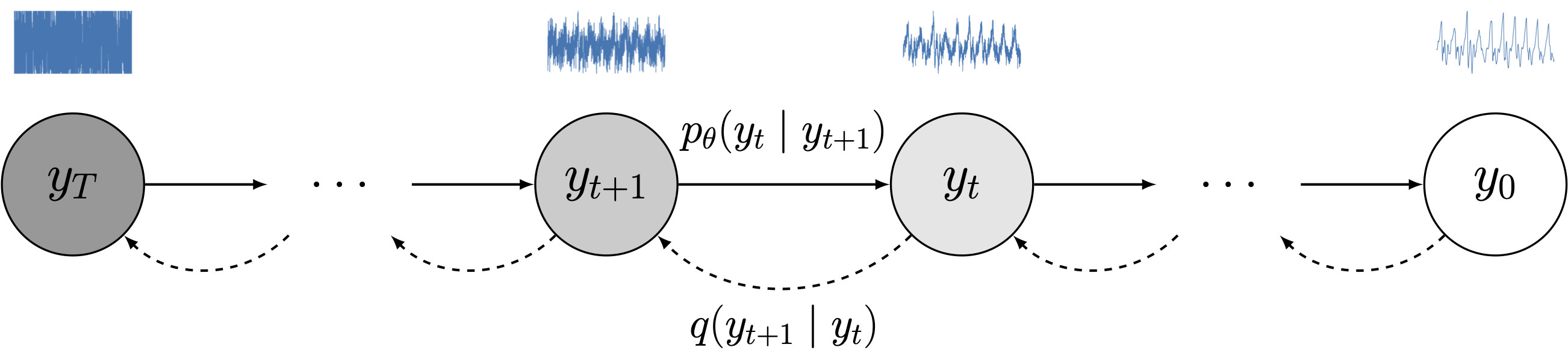
원래 논문에 넣고 싶었는데 4p라 분량이 모자라 못 넣은 Markov Chain 이미지. forward path(점선), reverse path(직선)
Training and Sampling
원본 데이터에 임의로 노이즈를 더하고 더해진 노이즈를 모델이 예측하는 방식으로 학습을 진행하고 sampling시에는 Gaussian noise부터 시작하여 우리가 원하는 data distribution으로 가는 방향에 해당하는 noise (score)를 예측하여 빼주는 것을 반복하게 됩니다. Diffusion model은 sampling이 여러 번 반복되어야 하기 때문에 오래 걸린다는 단점이 있지만 매우 높은 퀄리티의 sample을 생성할 수 있습니다.

DDPM의 training and sampling algoritihm
Conditional Diffusion Models as a Neural Vocoder
| DiffWave Architecture | WaveGrad Architecture |
|---|---|
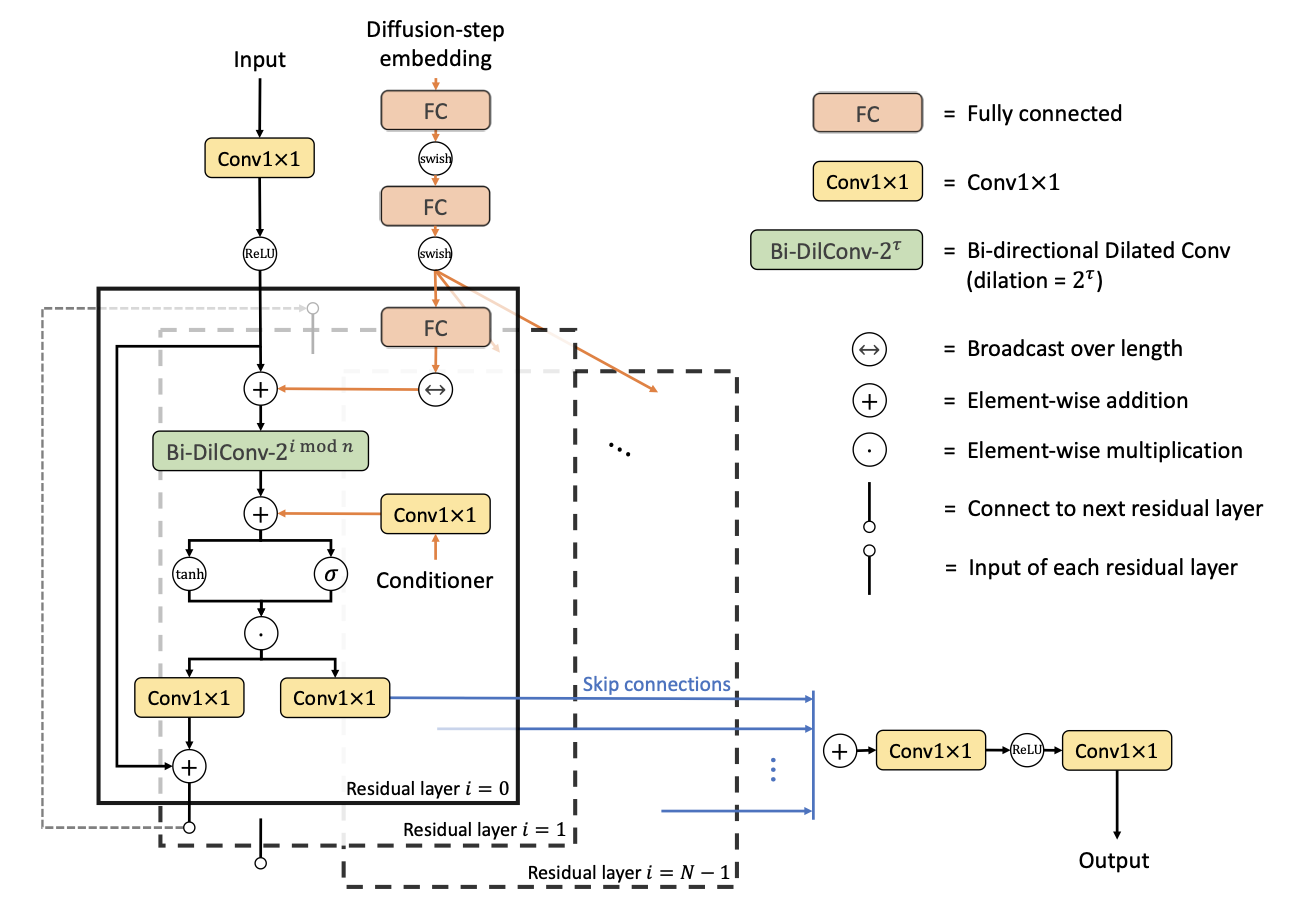 | 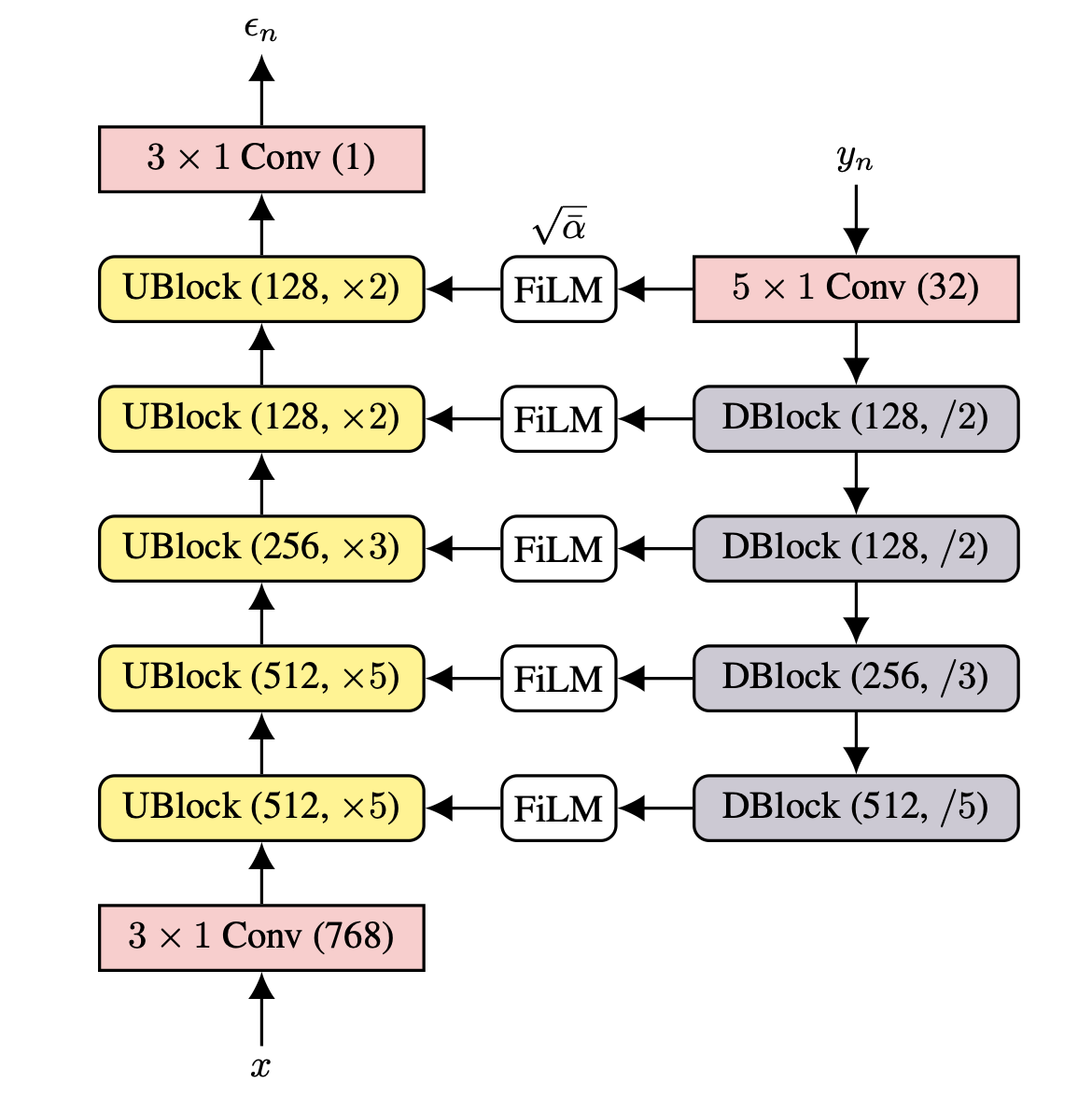 |
Diffusion model이 audio domain에 가장 먼저 적용된 분야는 neural vocoder인데요, neural vocoder는 Mel-spectrogram을 input으로 받아 raw audio를 생성하는 모델입니다. ICLR 2020에 동시에 DiffWave[4]와 WaveGrad[5]라는 diffusion-based neural vocoder 논문이 나왔습니다. Mel-spectrogram을 local condition으로 주고 마찬가지로 noise로부터 iterative하게 sampling 합니다. Mel-spectrogram과 output인 raw waveform이 linear하게 align 되어 있다는 점은 audio upsampling과 유사하여 적극적으로 audio upsampling 연구에 차용하였습니다.
사실 이 연구는 위의 논문들을 읽고 너무 감명 받아간지나서 시작하게 되었습니다.
NU-Wave
처음엔 목표를 48kHz를 타겟으로 하는 neural audio upsampling을 하는 것으로 잡았습니다. 그리고 구현이 상대적으로 간단한 위에 소개했었던 연구들을 구현하여 진행하였습니다. 그런데 상상 이상으로 결과가 좋지 않았습니다. Low frequency 부분은 크게 건드리지 않았지만 high frequency 부분들은 너무 과하거나 거의 없거나 했습니다. 그러던 중 위에서 설명한 diffusion model이 vocoder task에서 좋은 결과를 내었고 image domain에서도 1024x1024 해상도의 이미지를 sampling한 결과가 있어 바로 적용해 보기로 하였습니다.
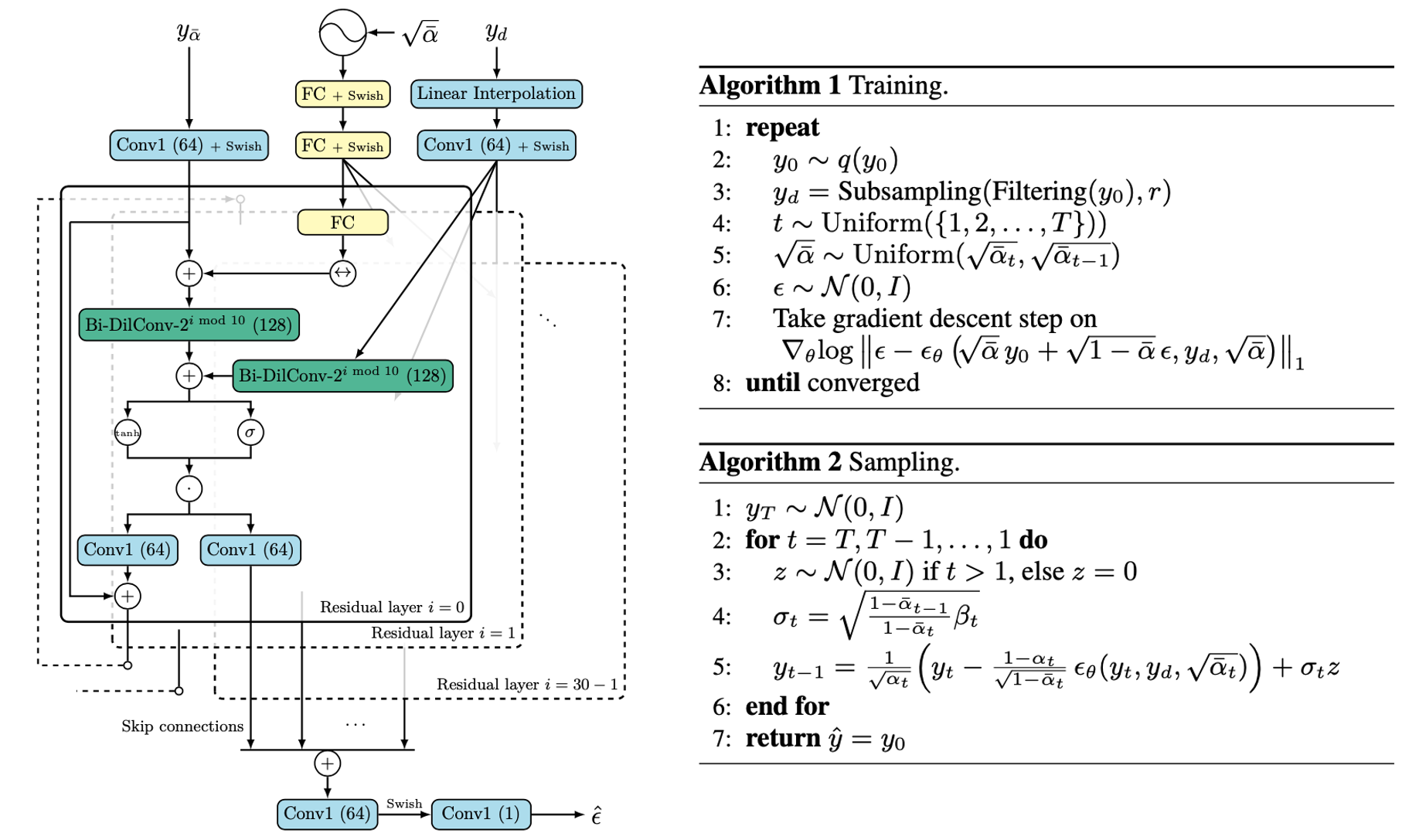
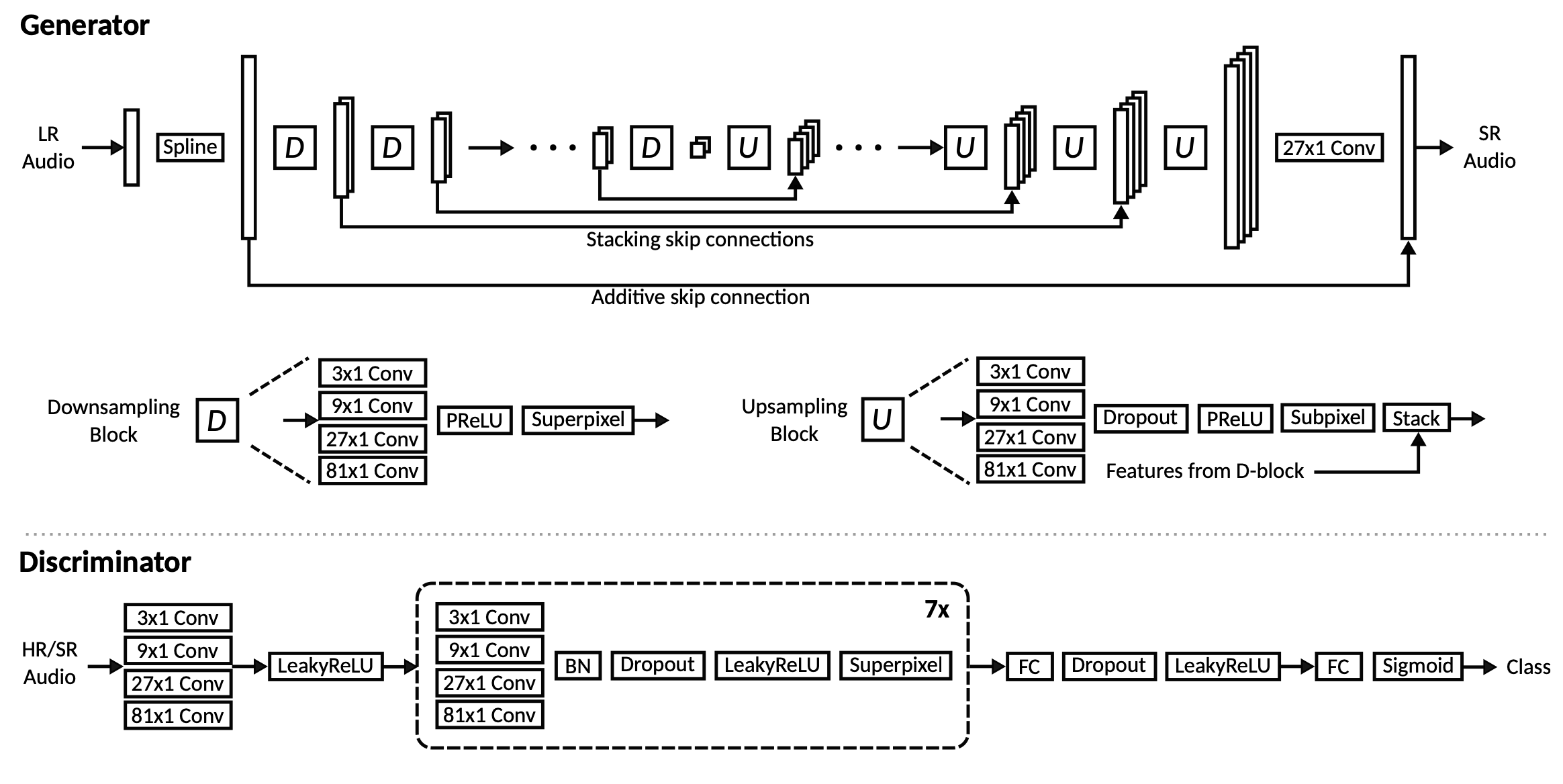
NU-Wave의 architecture와 algorithm
Neural vocoder 연구를 audio upsampling에 적용하기 위해 DiffWave와 WaveGrad를 많이 참고했습니다. 구조는 dilation convolution을 사용한 DiffWave의 구조가 U-Net like한 WaveGrad 보다 사이즈에 더 일반적일 것으로 생각하여 DIffWave의 구조와 최대한 유사하게 만들었고, WaveGrad의 경우 training 과정에서 continuous noise level training이라는 것을 적용하여 sampling시에 더 적은 수의 iteration으로 sampling을 하는 방법을 참고하였습니다.
Neural vocoder에서 사용된 값들을 upsampling에 사용하려고 하다 보니 몇가지 문제점이 있었습니다.
- Raw waveform을 condition으로 넣어줬을 때 receptive field가 너무 작아 condition이 별로 영향을 주지 못했다.
- 생각보다 sample이 많이 noisy 하다.
- 너무 high sampling rate를 target으로 하다 보니 computing power가 많이 필요했다.
1번의 경우 여러 가지를 시도하다 condition signal에도 Bi-DilConv를 적용했더니 갑자기 엄청나게 잘되기 시작하였습니다. Condition signal의 receptive field를 Bi-DilConv로 넓혀준 것이 효과가 있었다는 게 저희가 분석한 결과입니다.
2번의 경우 WaveGrad에서 제시했던 noise schedule, linear scale 등의 수치를 상당히 조절하고 학습을 오래 했더니 해결되었습니다. 아직 diffusion model이 많이 연구되었던 것이 아니다 보니 이런 hyperparameter들을 직접 여러 번 테스트해보는 것밖에는 답이 없었습니다.
3번의 경우 좋은 GPU를 제공해주는 MINDs Lab이라서 A100 두 대를 사용해서 해결했습니다.
해결 방법을 여러 가지를 시도해서 해결했다고 쓰긴 했지만 이 기간이 한 달 좀 넘었던 것 같습니다. 1월에 본격적으로 시작하여 구현은 2주안에 끝났는데 hyperparameter만 한달 넘게 고쳐가면서 정말 여러 가지를 시도해봤습니다. 한 달 넘는 시도 끝에 좋은 sample을 뽑아내는 정도가 되어 3월에는 논문 작성에 박차를 가했던 것 같습니다.
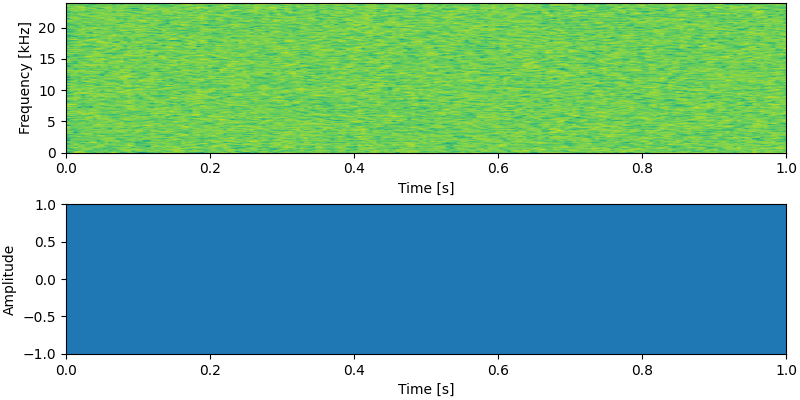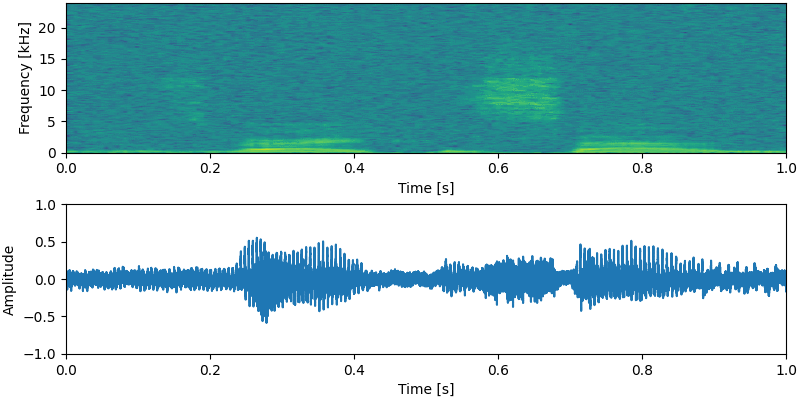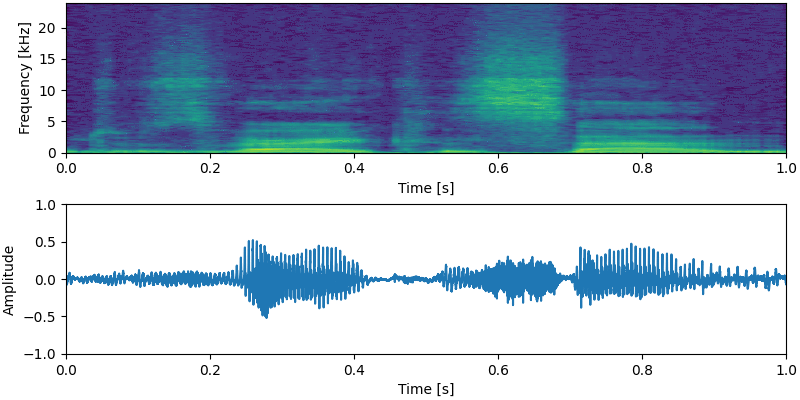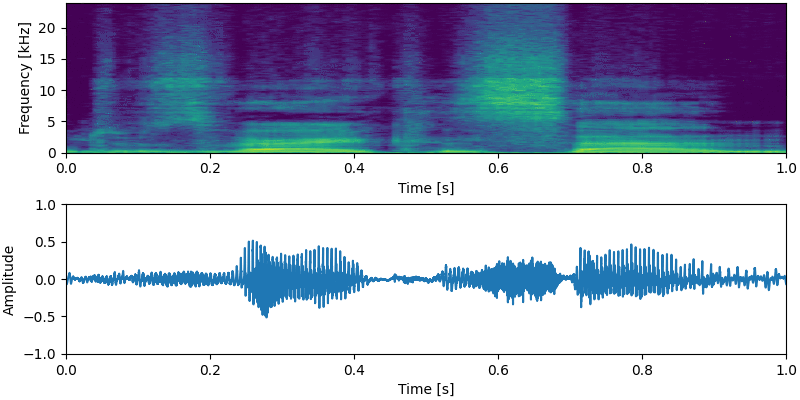
NU-Wave가 8번 만에 sampling하는 과정
Results
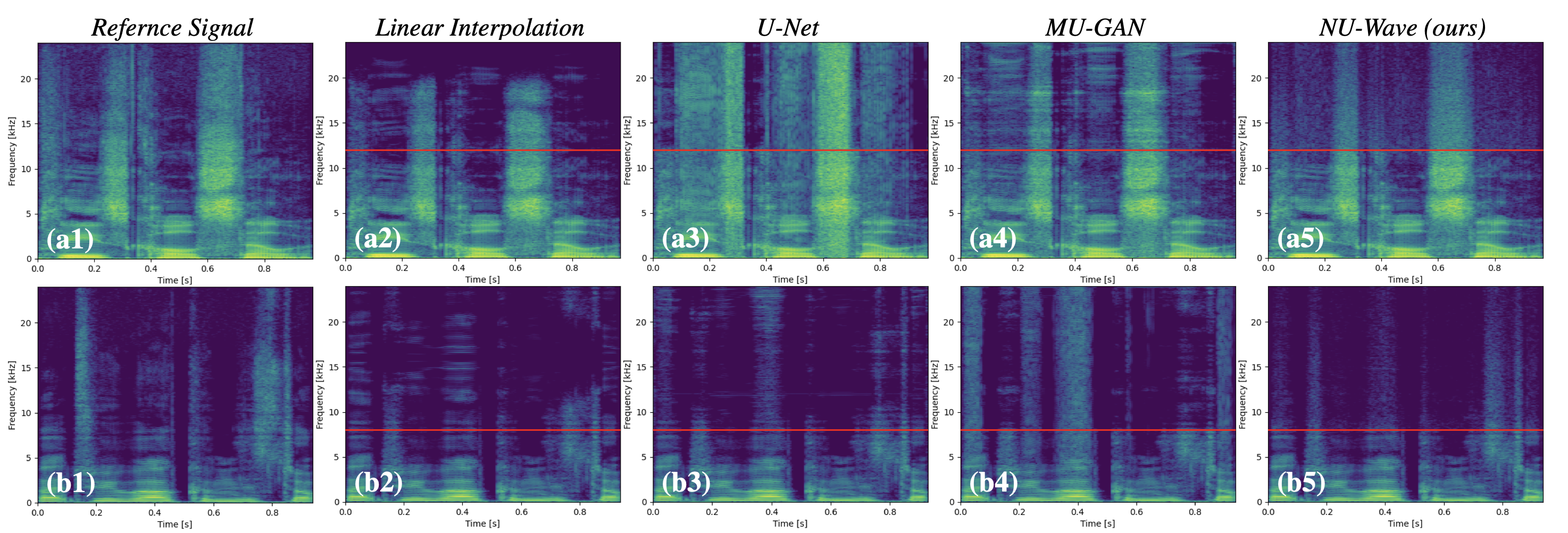
앞에서 소개한 것들과의 비교를 위한 spectrogram입니다. 제일 왼쪽 원본에 비해서 가운데 세개의 경우 과하게 기둥이 섰거나, Nyquist frequency 기준으로 대칭이 되거나 하는 현상을 보입니다. 하지만 NU-Wave의 경우 자연스럽게 high frequency 부분을 생성하는 것을 볼 수 있습니다.
| SNR, LSD | ABX accuracy |
|---|---|
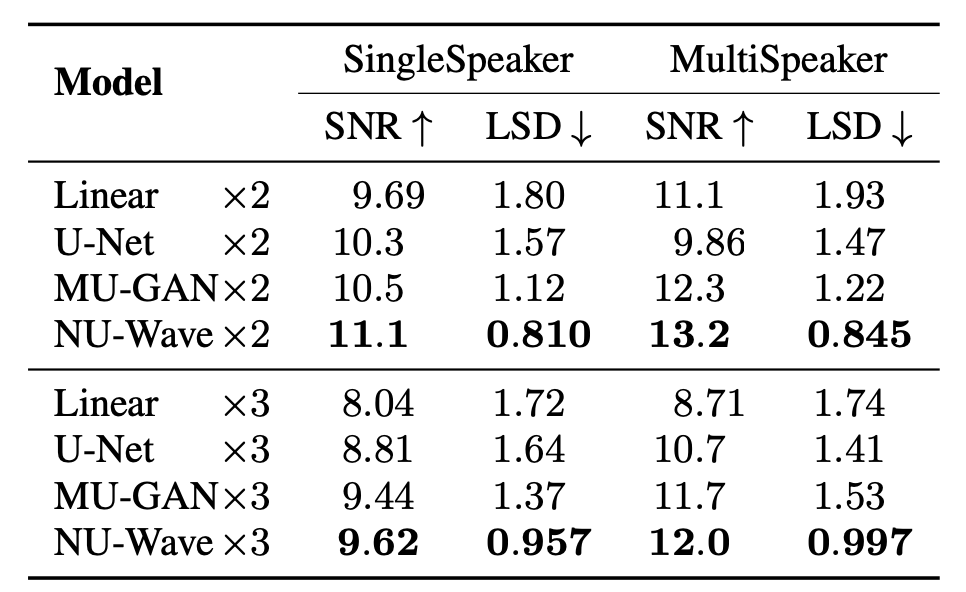 | 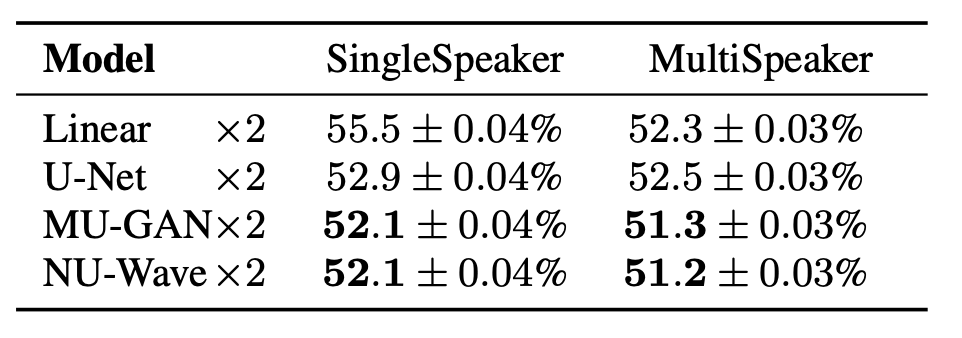 |
Audio upsampling task에서는 크게 3가지의 metric을 사용합니다. 원본과 downsampling한 신호를 다시 upsampling한 후 수치적으로 비교하는 SNR (signal-to-noise ratio), LSD (log-spectral distance)와 사람이 다른 종류의 A, B와 둘 중 하나를 뽑은 X 세가지를 들어보고 어느것인지 구분할 수 있는 ABX test의 정확도인 ABX accuracy가 있습니다. NU-Wave의 경우 SNR, LSD, ABX acc에서 3.0M의 parameter로 다른 모델들보다 높은 성능을 보였습니다.
Discussion
Downsampling 방식을 한정지어 아직 실제로 upsampling을 할 때는 문제가 생긴다는 점, diffusion model의 특성인지 high noise가 살짝 남는다는 점 등 개선해야할 부분이 많고 원래의 목표인 TTS에 적용하는 부분도 숙제로 남아있는것 같습니다. 자세한 내용은 논문을 참고해주시고 코드에 많은 스타⭐부탁드립니다.
9월에 INTERSPEECH 학회에서 봬요!
References
- V. Kuleshov, S. Z. Enam, and S. Ermon, “Audio super resolution using neural networks,” in Workshop of International Conference on Learning Representations, 2017. [arxiv]
- S. Kim and V. Sathe, “Bandwidth extension on raw audio via generative adversarial networks,” arXiv preprint arXiv:1903.09027, 2019. [arxiv]
- J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” in Advances in Neural Information Processing Systems, 2020, pp. 6840–6851. [arxiv]
- Z. Kong, W. Ping, J. Huang, K. Zhao, and B. Catanzaro, “Diffwave: A versatile diffusion model for audio synthesis,” in International Conference on Learning Representations, 2021. [arxiv]
- N. Chen, Y. Zhang, H. Zen, R. J. Weiss, M. Norouzi, and W. Chan, “Wavegrad: Estimating gradients for waveform generation,” in International Conference on Learning Representations, 2021. [arxiv]
TL;DR
- 최초로 16kHz/24kHz에서 48kHz로 upsampling 성공
- 최초로 diffusion model을 audio upsampling에 적용
- 적은 parameter number(3.0M)으로 다른 모델들을 능가