
Gyeongmin Kim, Minsuk Kim, Byungchul Kim, Heuiseok Lim. "CBITS: CryptoBERT Incorporated Trading System"
IEEE Access
CBITS: CryptoBERT Incorporated Trading System
안녕하세요, 마인즈랩 BRAIN NLP팀에서 근무하고 있는 김민석입니다. 이번에 IEEE Access에 accept를 받은 작업물에 대해서 이 블로그 포스트를 통해 간략하게 설명해보려합니다. 논문의 모든 부분을 설명한다기보다 중요한 부분만 간략하게 설명할 예정이니 자세한 내용은 논문을 통해 확인해주시면 감사하겠습니다.
평소에도 자연어 데이터를 사용한 금융 상품 가격 예측에 관심이 많은 편이고 특히 뉴스, 속보, 트윗등에 매우 민감한 자산인 암호화폐, 그리고 그중에서도 대장격인 비트코인의 추세 예측에 관심이 많았습니다. 따라서 암호화폐 분야에 domain-specific 언어모델을 사전학습 시켜봐야겠다고 생각했고, 공개된 한국어 언어모델이 많이 없는 상황이니 아예 한국어 사전학습된 암호화폐 language model (LM)을 만들어보자는 취지에서 시작하게 된 프로젝트입니다 (한국어 언어모델에 고집한 이유는 사실 더 있고 아래 추가로 설명하겠습니다). 현재는 huggingface에 공개된 영문 cryptobert 모델이 존재하긴하지만, 저희가 작업했을 당시에는 암호화폐쪽의 domain specific한 언어모델이 존재하지 않았습니다. 저희가 진행한 프로젝트가 거의 최초의 암호화폐 domain-specific한 언어모델을 만드려는 시도가 아니었을까 생각합니다. 만들어진 암호화폐 언어모델들을 활용해서 비트코인 선물시장 (BTC USDT Perpetual)에서 거래를 하는 투자봇을 만들어봤고 실전투자에도 투입시켜서 수익을 달성하는걸 확인했습니다. 매우 간단한 시도라서 사실 만들어진 언어모델로 훨씬 고도화된 시스템도 만들 수 있고, 단순 투자봇뿐만 아니라 암호화폐 관련 텍스트 유사도 측정등의 다양한 테스크에도 사용될 수 있다고 생각합니다. 이번 작업물이 accept를 받음으로써 crypto LM을 활용한 후속 연구를 추가로 더 하고싶은 motivation도 생겼습니다. 저희 한국어 crypto 언어모델들의 체크포인트는 huggingface에 공개되어 있습니다.
Contributions
- 코인니스 뉴스로 구성된 비트코인 가격에 대해서 해당 뉴스가 호재성인지, 악재성인지, 중립인지 레이블된 파인튜닝 데이터셋을 제작했습니다.
- 암호화폐 사전학습용 corpus를 구축하고 세가지 언어모델 (BERT, RoBERTa, DeBERTa)를 사전학습 시키고, 위에서 언급한 파인튜닝 데이터셋으로 비트코인 감성분류 테스크에 대해서 학습시켰습니다.
- 비트코인 선물시장에서 동작하는 간단한 분류기반 트레이딩 프레임워크를 제시했습니다.
- 해당 트레이딩 프레임워크에 crypto 언어모델을 사용하여 전처리된 정보를 추가로 사용하면 성능이 향상된다는걸 증명했습니다.
한국어 crypto 언어모델을 만든 이유
논문에서는 한국어 모델을 만든 여러가지 이유에 대해서 설명하지만 가장 결정적인 두가지 이유는:
- 코인니스라는 뉴스 소스에서 나오는 정보를 실시간으로 해석하는 언어모델을 만들고 싶었고 이 소스는 한국어로된 소스입니다
- 이렇게 만들어진 한국어 암호화폐 언어모델로 다양한 암호화폐 관련된 지표, 툴 혹은 투자봇을 만들어서 나중에 한국 시장을 상대로 서비스를 해보고 싶었습니다.
이 코인니스라는 뉴스 소스에 대해서 설명을 덧붙이자면 24시간, 365일동안 속보형식으로 구독자에게 텔레그램을 통해서 전달해주고 내용은 다양한 뉴스 소스들, 트위터, 그리고 온체인 모니터링 사이트 (e.g. whale alert) 같은 소스들을 계속 모니터링하여 정보를 정리해서 전달해줍니다. 하루에 평균 100-150개 정도의 속보가 올라옵니다. 텍스트 형식의 속보뿐만 아니라 다양한 지표 (RSI, fear-greed index 등등)과 같은 정보들도 정리해서 올라옵니다. 거기에 구독자들이 직접 참여해서 해당 뉴스가 bullish한 내용을 담고 있는지 bearish한 내용을 담고 있는지 투표를 하는 기능도 있습니다.
데이터 제작과정
Pre-training용 corpus의 경우, general text + crypto domain specific text로 진행되었고, crypto domain specific text는 다양한 한글 뉴스 소스 (파인튜닝에 사용된 코인니스 뉴스들은 제외), 해시넷같은 암호화폐 위키 관련 글들, 한국어로된 암호화폐 관련 논문, 암호화폐 관련 블로그글, 거래소에 실려있는 암호화폐 관련 설명글, 커뮤니티 사이등 다양한 소스에서 웹 크롤링을 실시해서 대략 1GB의 텍스트로 구성이 되었습니다. 시간적 여유가 많지 않아서 매우 큰 사전학습 corpus를 구축하지는 못했지만 그래도 아래 보이는 결과표처럼 암호화폐 domain에 사전학습 되지 않은 모델들보다 감성분류 테스크에서 성능이 더 좋은 모습을 보였습니다.
Fine-tuning 데이터의 경우, 코인니스에서 2018-01-19 부터 2022-04-16기간동안의 뉴스를 긁어와서 해당 뉴스들이 비트코인 가격에 대해서 호재, 악재, 중립인지 레이블링을 진행했습니다. 레이블링은 저와 다른 한명의 전업투자자가 진행을 했고, 시중에 나와있는 FinBERT모델 (그당시에는 영문 cryptobert도 존재하지 않았습니다)이 계산한 해당 뉴스의 감성점수, 코인니스의 bull/bear vote, 그리고 해당 뉴스가 나온 시점에 비트코인 가격이 어떻게 변동했는지등의 정보도 고려해서 레이블링이 진행되었습니다. 레이블링을 할때 비트코인 가격에 어떻게 영향을 끼칠지 위주로 레이블링을 해야했기 때문에 기준표를 만들어서 레이블러들이 기준표를 참고해서 레이블링을 진행하기로 합의를 봤었습니다. 총 18가지 기준이 있었고 해당 기준은 논문의 annotation guidelines에서 찾아보실 수 있습니다.
비트코인 감성 분류 태스크 성능

총 3개의 언어모델을 사전학습 시키고 fine-tuning 시켰습니다. CryptoBERT, CryptoDeBERTa는 마인즈랩 BRAIN-NLP에 근무하시는 용준영 선임님이 사전학습을 진행하셨고, CryptoRoBERTa는 고려대학교 박사과정이신 김경민님이 진행했습니다. Fine-tuning후에 downstream task에서의 성능을 저희 crypto LM들과 공개된 다국어 모델 (mBERT, XLM-RoBERTa)와 비교했을때 저희 crypto LM들의 성능 (F1 Score)가 더 우수한걸 확인했습니다. Crypto LM중에서 CryptoRoBERTa가 fine-tuning후에 가장 성능이 좋아서 이후에 언급된 실험들에는 CryptoRoBERTa가 사용되었습니다.
간단한 분류기반 트레이딩 프레임워크
만들어진 crypto LM을 가지고 매우 다양한 태스크를 수행할 수 있지만, 저희는 우선 이 모델들을 활용한 간단한 자동 투자봇을 제안했습니다. 투자봇은 naive하게 4시간마다 거래를 하게끔 만들었고, 수행할 수 있는 액션이 3개중 한개입니다: Long, Short, Hold. 현재시간부터 이후 4시간동안 가격이 0.75% 이상 오를 것 같으면 레이블 0 (Long), 0.75% 이상 내릴 것 같으면 레이블 1 (Short), 0.75% 미만으로 변동할 것 같으면 레이블 2 (Hold)로 설정하고 모델 학습을 진행했습니다.
| Labeling Rule |
|---|
 |
이렇게 학습해서 모델의 예측 성능이 좋다면, 비트코인의 상승장, 하락장, 횡보장 상관없이 모델이 대응할 수 있고 수익을 낼 수 있다고 생각했습니다. 이런 프레임워크에서 crypto LM을 통해서 계산된 감성점수를 추가로 활용하면 투자봇의 예측성능이 더 좋아질까?가 저희가 실험하고 싶었던 부분이었습니다.
| CBITS Architecture |
|---|
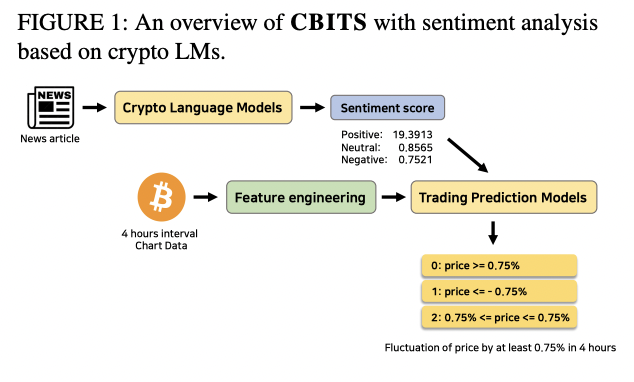 |
감성점수를 모델에 사용하는 방법이 여러가지가 있는데 해당 논문에서는 매우 간단한 접근법을 실험해봤습니다. 4시간동안 나온 뉴스들의 평균 감성점수를 계산하고, 이 감성점수와 차트 입력 피처들을 모델에 입력으로 넣어서 학습해주는 방법을 사용했습니다. 차트 입력 피처들은 단순히 open, high, low, close, volume뿐만 아니라 다양한 지표들 (주로 volatility와 관련된)을 사용했고, 학습에 사용한 모델들은 LSTM, XGBoost, TabNet 이렇게 3가지였습니다. 입력 데이터를 tabular 형식으로 전처리해서 접근했기 때문에 tabular 데이터에 강한 XGBoost 그리고 XGBoost보다 다양한 benchmark task에서 성능이 더 좋았다는 TabNet을 사용해서 실험하기로 했었고 결과는 TabNet이 가장 우수했습니다.

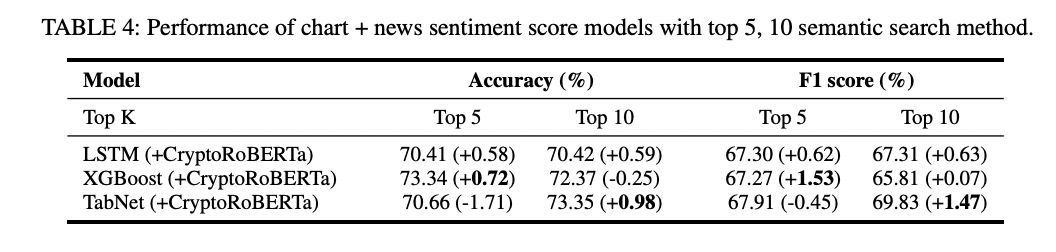
뉴스 감성점수를 추가하니 모든 모델의 accuracy와 F1 score이 더 좋아진걸 볼 수 있습니다. 추가적으로 다른 재밌는 실험도 진행했는데 가끔 매우 긴 코인니스 뉴스/속보의 경우 BERT계열 모델의 512 토큰 제한때문에 truncation이 이루어집니다. 뉴스 제목과 가장 유사한 본문 문장 top k (k = 5, 10)개를 이용해서 감성점수를 뽑았을때 몇몇 모델의 경우 추가 성능 향상이 있다는걸 확인했습니다.
Backtest 성능비교
Test set에 대해서 단순 accuracy와 F1 점수보다는 실제로 이 트레이딩 프레임워크가 얼마만큼의 수익률을 내는지가 더 유용한 지표일거라고 생각해서 백테스트도 진행했습니다. 저희 모델의 경우 가장 성능이 좋았던 TabNet 모델들과 다른 트레이딩 기법들 (랜덤하게 투자하는 Monkey Trader, 단순 Buy and Hold, OLMAR)와 비교를 했고, 저희 모델의 경우 take profit 0.75%, 기존 거래소의 수수료의 두배를 고려해서 (실제 거래에서는 bid-ask spread, slippage등 요소가 많기 때문) 수익률을 계산해봤습니다. 결과적으로 다른 방법들보다 수익률이 압도적으로 좋은 모습을 보였습니다.
| Backtest 결과 |
|---|
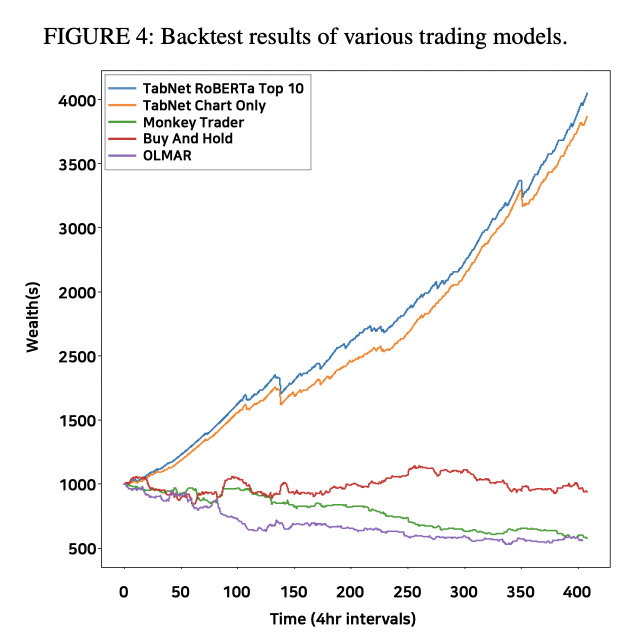 |
Live Run 성능, 그리고 한계점들
백테스트 성능만으로 실제 투자 수익률에 대해서 판단하기에 한계가 있다고 생각해서 논문에서 제시한 프레임워크와 모델 체크포인트를 활용해서 실제로 투자를 해보면서 수익률을 관찰해봤습니다. 약 $100 정도의 초기 시드를 가지고 Bybit라는 선물 거래소에서 BTC/USDT 투자를 시작했고 거의 2주정도의 기간동안 돌려놓은 결과 단순 buy and hold (장기투자)보다 우수한 수익률을 기록했습니다. 더 오래동안 돌려서 관찰해보고 싶었지만 논문 제출일정때문에 추가적인 관찰결과는 논문에 실을 수 없었습니다.
| Liverun 결과 |
|---|
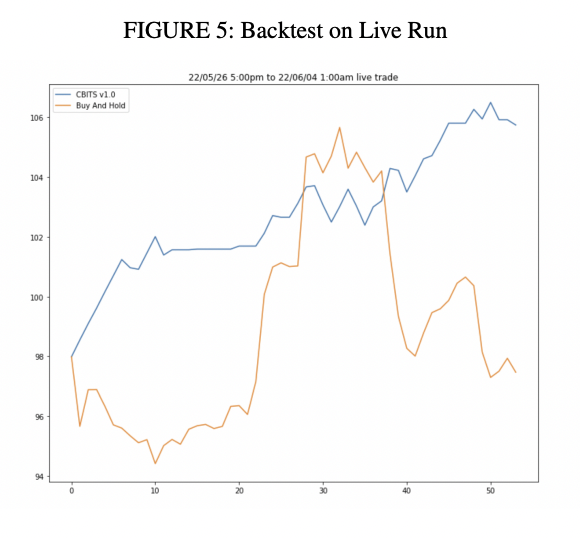 |
몇가지 limitation들도 보였는데 일단은 take profit이 0.75%이기 때문에 게속 상승만 하는 구간에서는 단순 long이나 buy and hold 전략보다 수익률이 작을 수 있습니다. 반대로 계속 하락하는 구간에서는 단순 short 전략보다 수익률이 적을 수 있습니다. 그리고 마땅한 stop loss mechanism도 없다는게 큰 단점입니다. Secretary problem 같은 방식을 응용한 exit 기법이나 언제 exit하는게 최적인지 판단하는 강화학습 기반 stop loss전략을 도입해봐도 좋을 것 같습니다.
Future Work
- 단순하게 sentiment score를 활용하는 모델보다는 text들의 임베딩을 뽑아서 차트 피처의 임베딩과 모델 내부에서 결합되고, text와 chart의 임베딩을 뽑는 인코더들을 전부 end-to-end로 학습시키는 모델을 생각해볼 수 있습니다.
- Sentiment classification 이외에도 crypto text semantic similarity search, crypto text NER, crypto pump and dump classification등 다양한 테스크에도 저희의 LM이 적용가능합니다. 특히 유사한 암호화폐 뉴스 서치 시스템을 현재 개발중이고 관련해서 후속 논문 작업도 진행해보고 있습니다.
References
- J. Abraham, D. Higdon, J. Nelson, and J. Ibarra. Cryp-tocurrency price prediction using tweet volumes and sentiment analysis. SMU Data Science Review, 1(3):1, 2018.
- D. Araci. Finbert: Financial sentiment analysis with pre-trained language models. arXiv preprint arXiv:1908.10063, 2019
- S.. Arik and T. Pfister. Tabnet: Attentive interpretable tabular learning. Proceedings of the AAAI Conference on Artificial Intelligence, 35(8):6679–6687, May 2021. URL https://ojs.aaai.org/index.php/AAAI/article/view/16826
- . Barnwal, H. P. Bharti, A. Ali, and V. Singh. Stacking with neural network for cryptocurrency investment. In 2019 New York scientific data summit (NYSDS), pages 1–5. IEEE, 2019
- Z. Boukhers, A. Bouabdallah, M. Lohr, and J. Jürjens. Ensemble and multimodal approach for forecasting cryptocurrency price, 2022. URL https://arxiv.org/abs/2202.08967
- I.Chalkiadakis, A. Zaremba, G. W. Peters, and M. J.Chantler. On-chain analytics for sentiment-driven sta-tistical causality in cryptocurrencies. Blockchain: Research and Applications, 3(2):100063, 2022. ISSN 2096-7209. . URL https://www.sciencedirect.com/science/article/pii/S2096720922000033.
- Q. Chen. Stock movement prediction with financial news using contextualized embedding from bert, 2021.URL https://arxiv.org/abs/2107.08721.