



![]()

Hyunjae Cho, Wonbin Jung, Junhyeok Lee, and Sang Hoon Woo. "SANE-TTS: Stable And Natural End-to-End Multilingual Text-to-Speech."
INTERSPEECH 2022
SANE-TTS: Stable And Natural End-to-End Multilingual Text-to-Speech
안녕하세요. MINDsLab Brain팀에서 음성합성 연구를 하고 있는 조현재입니다.
오늘은 저희 Brain팀에서 같이 쓴 SANE-TTS paper가 INTERSPEECH 2022에 accept되었다는 좋은 소식과 함께 소개해드리는 시간을 가지려 합니다.
Contributions
- SANE-TTS는 안정적이고 자연스러운 다국어 음성을 합성합니다.
- 이 논문에서 제안한 speaker regularization loss는 기존 다국어 TTS 모델에서도 사용된 방법인 domain adversarial training과 비슷한 수준의 퀄리티 향상을 이끌어냅니다.
Introductions
다국어(Multilingual) TTS 모델을 훈련시키는 가장 간단한 방법은 무엇일까요? 당장 머리에 떠오를 만한 방식은, 모델이 음성 합성을 지원할 모든 화자로부터 모델이 사용할 모든 언어에 대해 음성 데이터를 모아 만든 다국어 음성 데이터셋을 사용하는 방식일 겁니다. 그러나 이런 방식은 현실적으로 불가능한데, 왜냐하면 이 방식이 가능하려면 우선 모든 화자가 여러 언어를 유창하게 구사할 줄 알아야 하고, 화자가 한 명 늘어날 때마다 모든 언어에 대해 데이터를 모아야 해서 상당한 비용 부담이 발생하기 때문입니다. 그래서 현실적으로 가능한 방식은 서로 다른 화자들이 녹음한 단일언어 데이터셋을 언어별로 모아 훈련용 데이터셋을 구성하는 것입니다. 예를 들어, 화자 A의 한국어 음성 데이터와 화자 B의 영어 음성 데이터를 모아 쓰는 것이죠. 하지만 이 경우 화자가 데이터셋 내에서 사용하지 않은 언어로도 다국어 TTS가 발화가 가능해야 ‘모든 화자에 대해 학습에 사용된 모든 언어로 음성 합성을 한다는 목표’를 달성할 수 있습니다. 쉽게 말하자면 한국어 화자 A의 목소리로도 자연스럽게 영어 음성을 합성할 수 있어야 합니다. 이렇게 훈련 데이터셋에서 특정 화자가 사용한 언어와 다른 언어로 음성을 합성하는 것을 cross-lingual speech synthesis라 부르며, 위와 같은 이유로 다국어 TTS 모델을 구현하기 위해 cross-lingual speech synthesis를 자연스럽고 안정적으로 만드는 일은 매우 중요합니다.
지금까지 제안된 기존 다국어 TTS 모델들은 대부분 Tacotron[1] 기반 모델입니다. 하지만 Tacotron 기반 다국어 TTS 모델들은 자기회귀적(autoregressive)으로 텍스트와 음성 사이의 alignment를 계산하기 때문에 문제가 발생할 수 있습니다.[2] 우선 자기회귀적 모델은 작은 attention error에도 민감하게 반응하여 틀린 alignment를 계산하고 이는 음성 합성 시 단어를 반복 혹은 누락하는 문제로 이어집니다. 또한, 자기회귀적으로 attention을 생성하다 보면 발화 길이의 직접적인 제어가 어려워져 부자연스러운 속도로 발화할 가능성도 있습니다. 이러한 문제들을 피하기 위해, 저희는 비자기회귀적 모델들 중 VITS[3]를 기반으로 하여 SANE-TTS를 설계했습니다.
VITS
| VITS at training | VITS at inference |
|---|---|
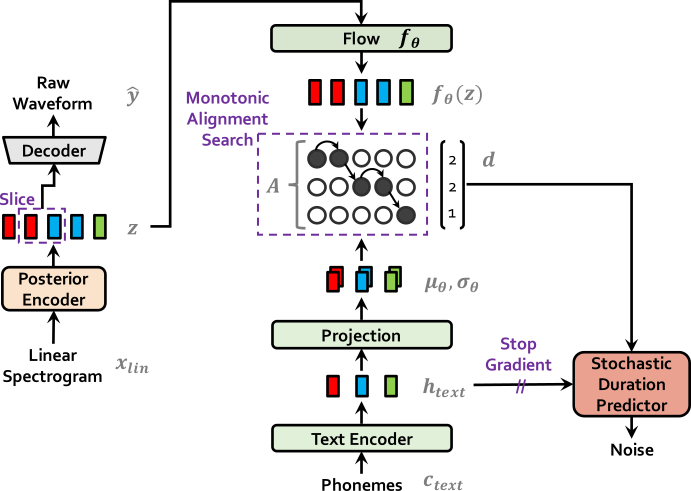 |  |
전체적인 VITS의 구조는 linear spectrogram을 posterior encoder를 이용해 latent 로 변환한 다음 다시 decoder를 통해 음성을 생성하는 VAE 구조입니다. 이 때 text encoder를 통해 나온 결과값과 latent 를 flow 모듈에 넣고 나온 결과값을 이용해 input text와 target speech간의 alignment를 계산합니다. 이 과정에서 monotonic alignment search가 사용되며 나온 duration 정보를 통해 duration predictor를 훈련시킵니다.
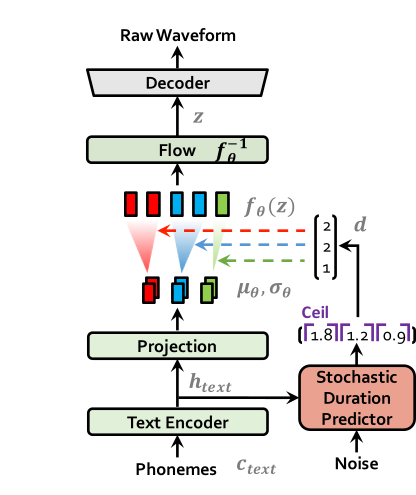
Inference 과정에서는 text encoder에서 나온 결과값을 duration predictor가 예측한 duration을 통해 speech 길이에 맞게 늘려줍니다. 그 다음 flow reverse 과정과 decoder를 거쳐 speech를 합성합니다.
VITS 모델은 non-autoregressive한 모델이자 하나의 모델로 text를 speech로 만드는 end-to-end 모델입니다. VITS에 대한 더 자세한 내용은 VITS post에서 보실 수 있습니다.
SANE-TTS
| SANE-TTS at training |
|---|
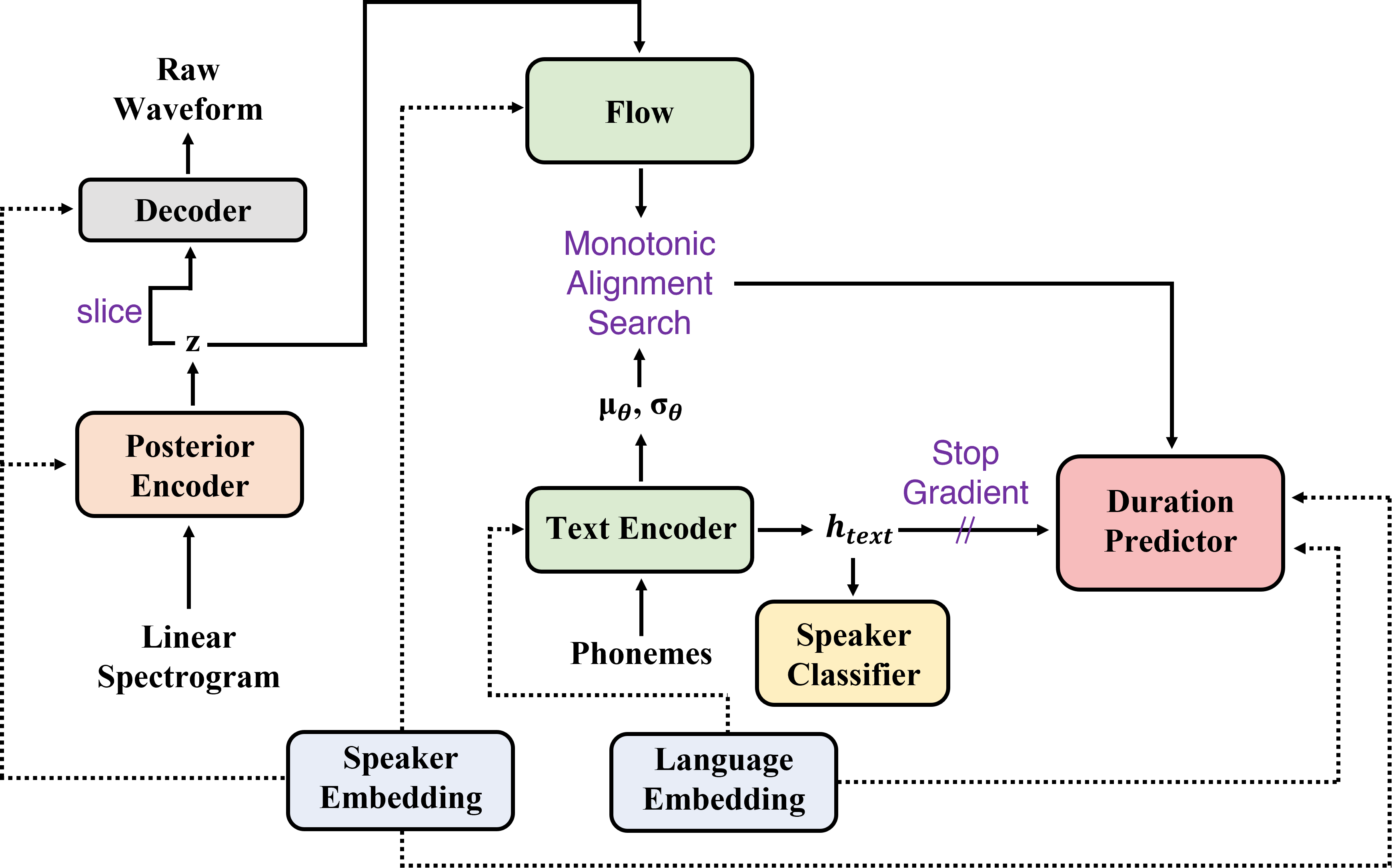 |
Language embedding
다국어 TTS 모델의 경우에는 여러 언어를 사용하기 때문에 SANE-TTS는 language embedding을 이용해 언어를 구별합니다. 특히 text representation을 직접 받는 text encoder와 duration predictor 모듈에게만 language embedding을 제공하여 각 언어를 구별할 수 있도록 도와줍니다. Duration predictor에서는 기본 VITS 세팅에서의 speaker embedding과 동일하게 language embedding 역시 convolution layer에 통과시킨뒤 text representation에 더하는 식으로 언어 정보를 모듈에 줍니다.
Text encoder에서는 Nekvinda and Dusek[4]가 제안한 parameter generation을 사용해 언어 정보를 전달합니다. 이는 하나의 text encoder 모듈로 다양한 언어에 맞는 text representation을 생성하기 위한 방안으로, parameter generator가 language embedding을 받아 언어 정보가 들어있는 parameter를 생성한 다음, parameter들을 text encoder의 각 레이어에 더하는 방식입니다. Text encoder의 여러 부분에 언어 정보가 제공되었기 때문에 각 언어에 최적화된 text representation을 만들게 됩니다.
Domain adversarial training
훈련 데이터에서 화자마다 사용하는 text가 다르기 때문에 모델을 훈련하는 과정에서 text 정보와 화자 정보가 서로 영향을 줄 수 있습니다. 이로 인해 발생할 수 있는 편향문제를 막기 위해 기존 다국어 TTS 모델들[4][5]은 domain adversarial traing(DAT)[6]을 사용했습니다. SANE-TTS 역시 DAT를 적용하여 위의 문제를 해결했습니다. SANE-TTS에 대한 DAT 적용 방식은 아래와 같습니다.
먼저, gradient reversal layer와 fully connected layer로 이루어진 speaker classifer에 text encoder의 결과값인 를 넘겨줍니다. Gradient reversarial layer는 흐르는 역전파 gradient의 부호를 반대로 바꾸는 역할을 수행합니다. 그 다음 speaker classifier를 화자 분류의 정확도를 측정하는 cross-entropy loss를 통해 훈련하게 된다면, 오히려 는 화자 분류의 정확도가 낮아지도록 화자 정보가 없어지는 방향으로 훈련이 진행됩니다. 따라서 DAT를 적용하면 text encoder는 화자에 독립적으로 학습하여 편향 문제를 해결합니다.
Speaker regularization loss
다국어 TTS 모델 훈련 데이터에서 보통 한 화자는 단일언어에 대해서만 음성 데이터가 있기 때문에 화자 정보가 언어에 편향될 수 있습니다. 특히 duration predictor에서는 화자 정보와 언어 정보가 동시에 필요하기 때문에 화자 정보의 언어 편향이 큰 문제를 발생시킬 수 있습니다. 이에 SANE-TTS는 duration predictor 내 화자 정보의 언어 편향 문제를 해결하기 위해 speaker regularization loss를 추가합니다. Speaker regularization loss의 정확한 계산식은 위와 같습니다. 는 하나의 batch를 의미하며 는 datapoint 에서 화자의 speaker embedding을 의미합니다. 또한 는 kernel size가 1인 convolution layer를 의미합니다. 이러한 loss를 통해 hidden speaker representation인 는 평균값이 언어에 관계없이 영벡터에 가까워지도록 압력을 받게 되고 이에 따라 화자 정보는 언어와 분리됩니다. (Speaker regularization loss의 자세한 역할 설명은 Results의 Figure 4에 나와있습니다.)
Deterministic duration predictor
기존 VITS에서는 다양한 duration을 확률적으로 예측하는 stochastic duration predictor(SDP)를 사용했습니다. 하지만 Casanova et al.[7]는 '여러 언어를 다뤄야 하는 상황에서는 SDP가 때때로 부자연스러운 duration을 예측한다.'라고 언급한 바 있습니다. 다국어 TTS 모델의 경우 cross-lingual speech synthesis의 안정성을 높이는 것이 중요하기 때문에 저희 SANE-TTS에서는 SDP를 deterministic duration predictor(DDP)로 교체합니다.
| SANE-TTS at inference |
|---|
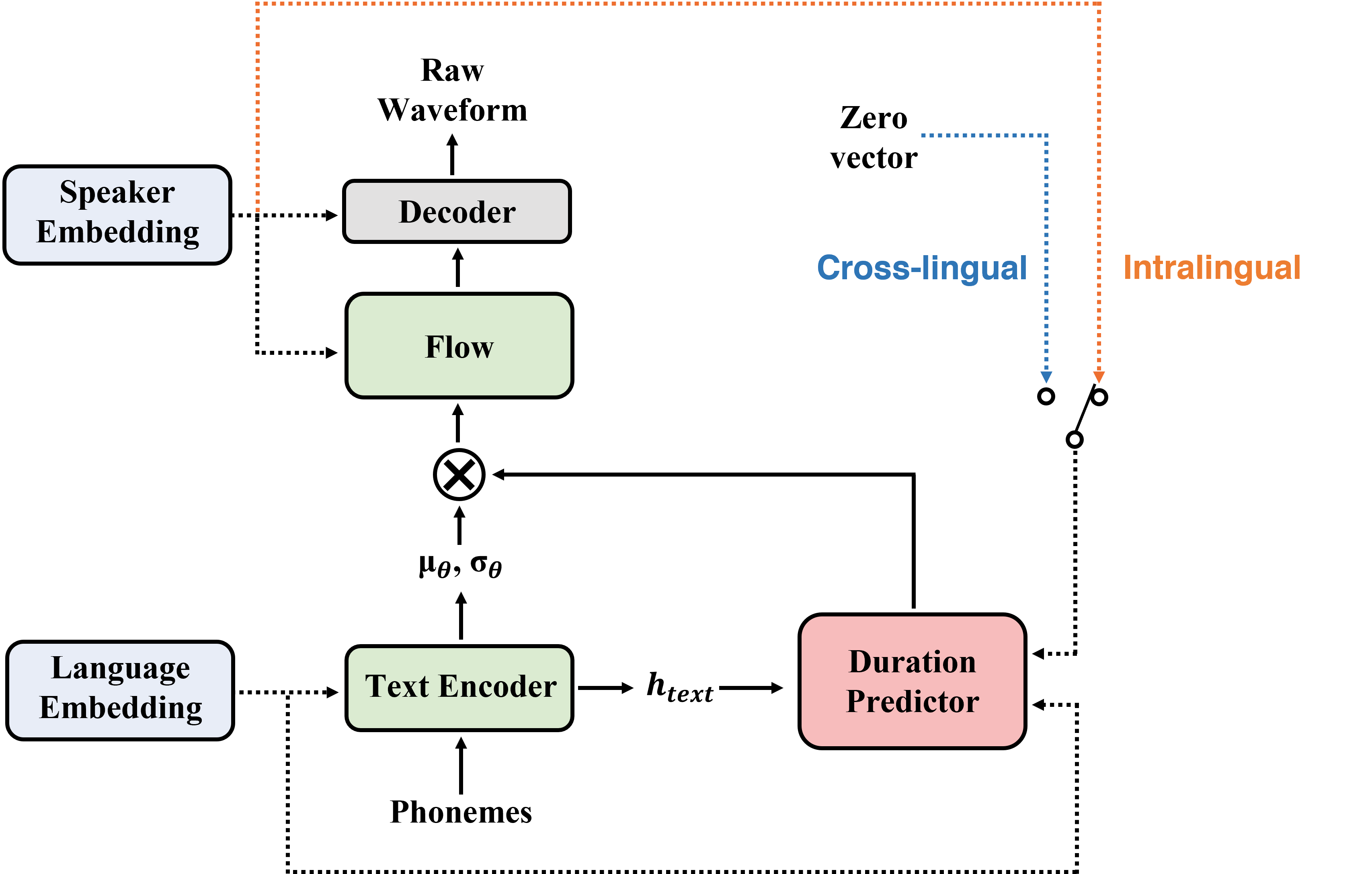 |
Inference procedure
영어 화자가 한국어 음성을 말할 때 기본적인 톤, 세기 등은 어느정도 예측이 가능하지만 발화의 duration은 예측하기 힘듭니다. 그 이유는 톤, 세기 같은 특성들은 화자 자체의 특성에 가까워 언어와 관련성이 덜하지만 발화의 duration은 언어와 크게 맞닿아 있기 때문입니다. 따라서 다국어 TTS 모델에서 영어 화자의 특성을 그대로 사용하여 한국어 음소의 duration을 예측한다면 부자연스럽게 들릴 뿐 화자 특성이 반영된다고 보기 어렵습니다. 이러한 문제를 해결하기 위해 저희는 cross-lingual inference 단계에서 약간의 수정을 가했습니다.
SANE-TTS의 duration predictor에 speaker regularization loss를 추가했기 때문에 hidden speaker representation들은 영벡터 근처에 위치하게 됩니다. 이를 이용해 cross-lingual speech synthesis 과정에서 duration predictor에 speaker embedding 대신 가까운 값인 영벡터를 집어넣습니다. 따라서 SANE-TTS는 cross-lingual speech inference를 할 때 화자가 달라지더라도 duration predictor가 동일한 duration을 예측합니다. 이 방법을 통해 cross-lingual하게 합성한 음성의 안정성을 높이고, duration에 언어가 다른 화자 정보를 반영할때 생기는 모호함을 없앨 수 있습니다.
Experiments
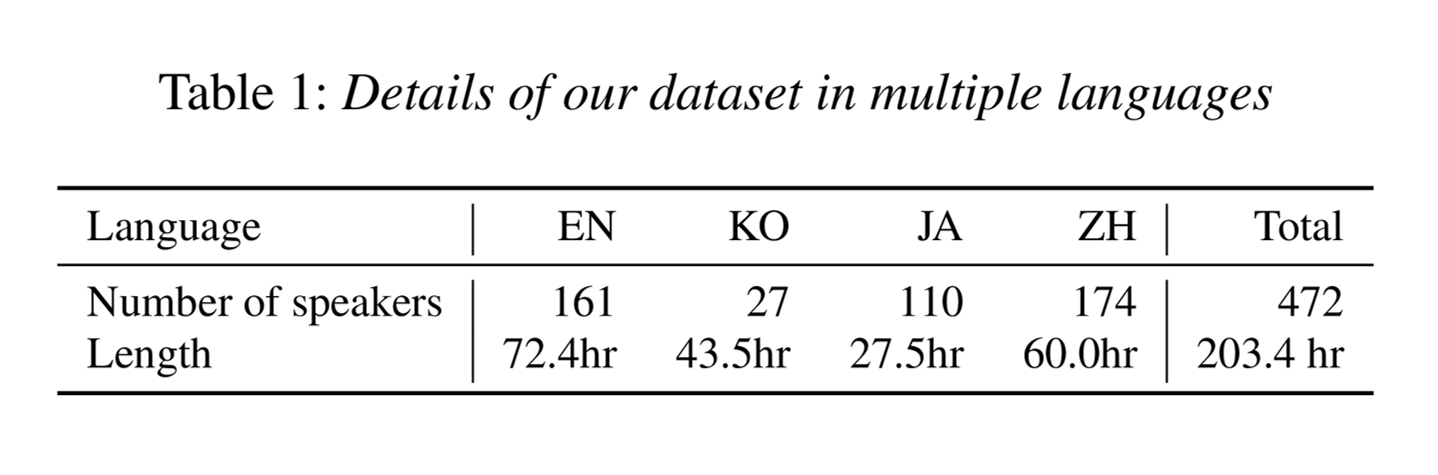
훈련 데이터셋에는 영어(EN), 한국어(KO), 일본어(JA), 중국어(ZH) 화자가 있습니다. 위 표에 나와있듯이 총 472명의 화자와 203.4시간의 음성을 사용하고 음성 데이터의 5%는 validation에 사용됩니다.
음성의 품질을 측정하기 위해 MOS 평가를 진행합니다. MOS 평가는 음성의 품질을 평가하기 위해 사용되는 주관적 기법으로, 평가자들이 음성에 대해 1~5점 사이의 평점을 매겨 평점이 높을수록 성능이 높다고 판단하는 방식입니다. Metric으로는 naturalness MOS와 similarity MOS를 사용하는데, 각각 naturalness MOS는 합성된 음성이 얼마나 자연스럽게 들리는지, similarity MOS는 합성된 음성의 화자가 원래 음성의 화자와 얼마나 비슷하게 들리는지에 대한 MOS 평가 점수입니다.
Results
Speech synthesis quality
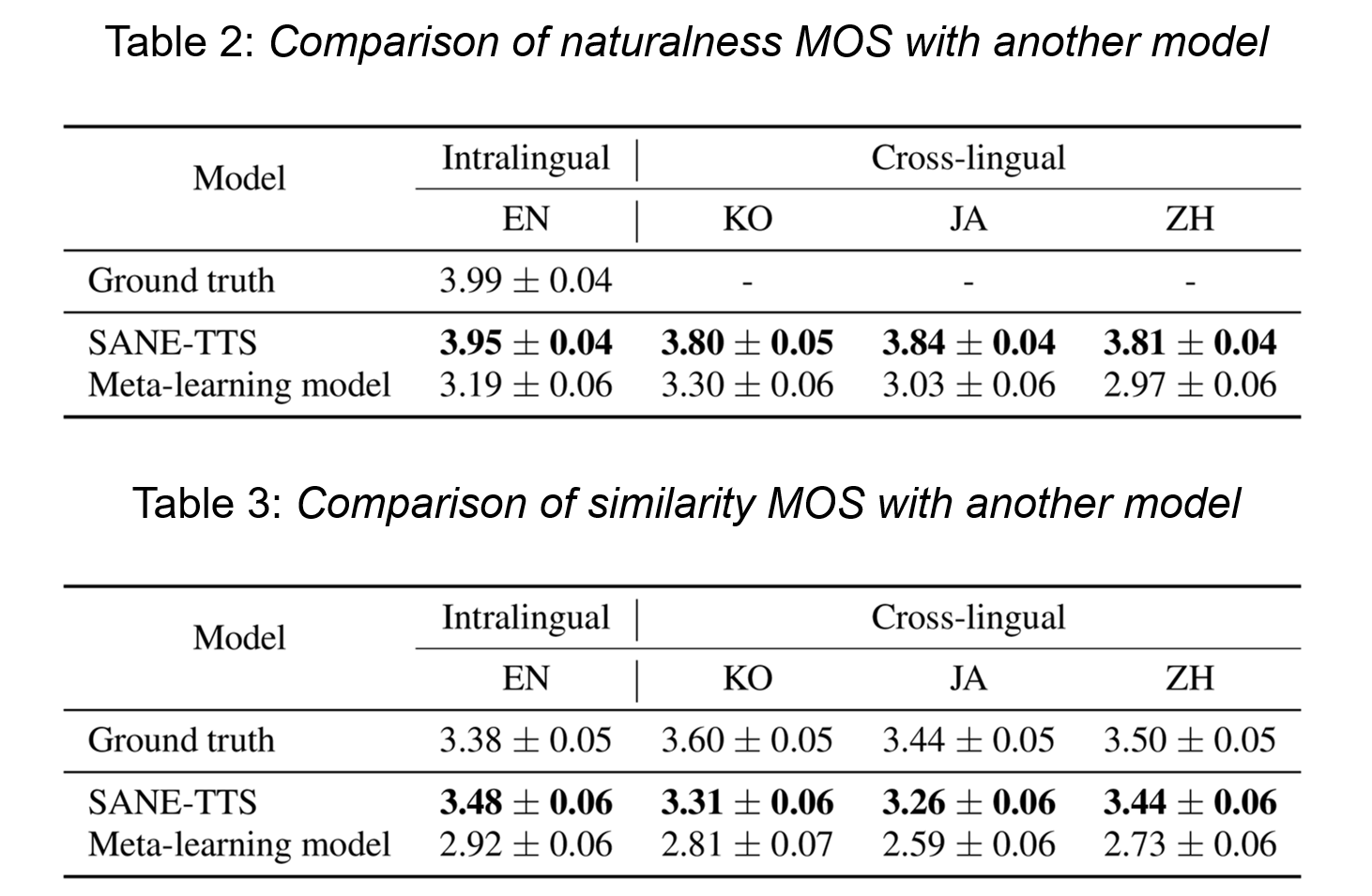
SANE-TTS와 다른 다국어 TTS model인 Meta-learning model[4][8]를 비교한 결과 음성의 자연스러움(naturalness MOS)과 화자의 유사성(similarity MOS) 모두 SANE-TTS가 더 좋은 결과를 냈습니다. 특히 cross-lingual speech synthesis 시 SANE-TTS는 화자에 관계없이 일정한 duration을 예측하기 때문에 안정적인 음성을 합성할 수 있습니다.
Ablation study
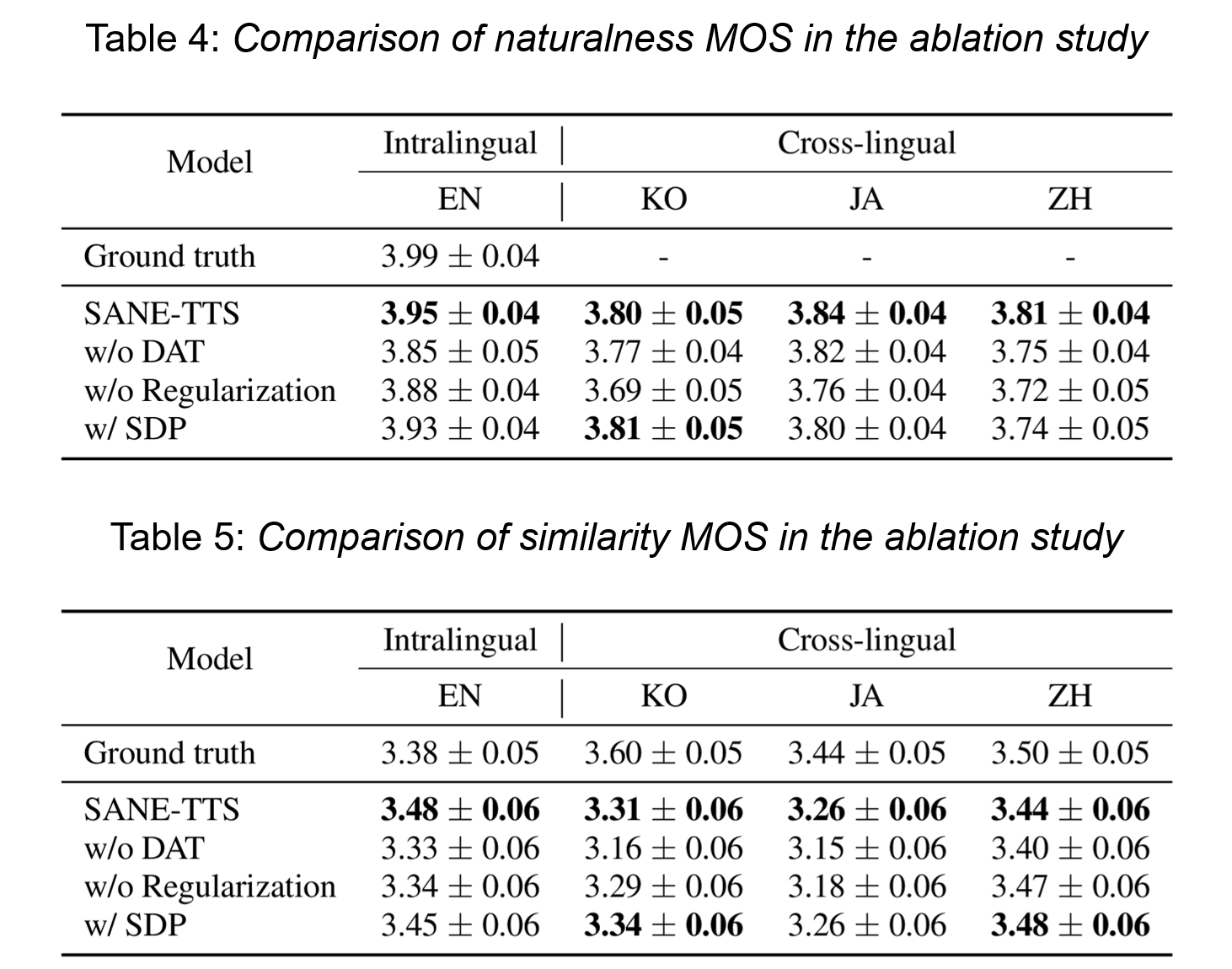
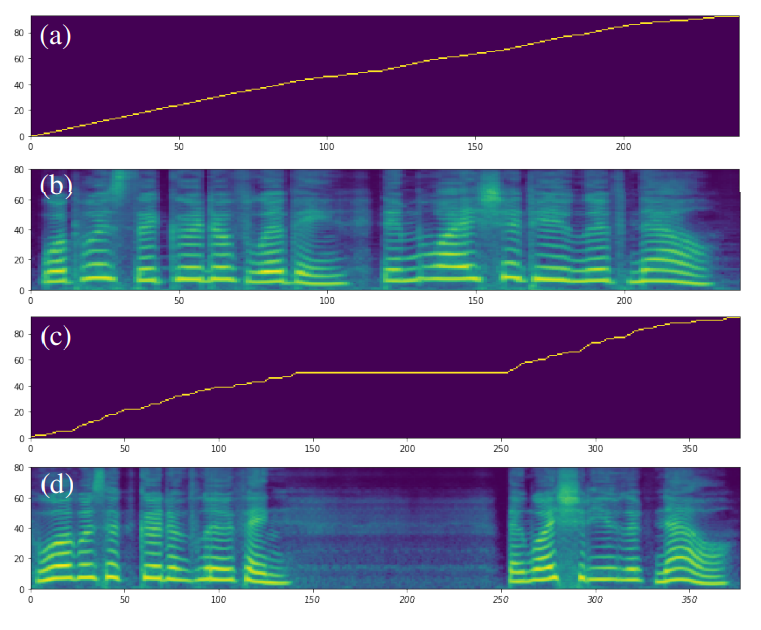
DAT를 적용하는 것과 speaker regularization loss를 추가하는 것 모두 음성의 자연스러움과 화자의 유사성을 향상시킵니다. 반면에 SDP를 사용하는 것과 기본인 DDP를 사용하는 것에는 통계상으로 유의미한 차이가 보이지 않습니다. 하지만 SDP는 종종 부자연스러운 duration을 생성한다는 문제점이 존재합니다. Figure 3에 나와있는 예시를 보시면 SDP가 잘못된 duration을 생성하여 합성된 음성의 중간에 긴 침묵이 발생합니다. 이런 잘못된 경우를 방지하기 위해 SANE-TTS는 비교적 안정적으로 duration을 생성하는 DDP를 사용합니다.
| Figure 3: DDP와 SDP를 사용한 모델이 생성한 alignments와 mel spectrograms figure입니다. 사용한 text는 “What was the good of living, and why should he live now?”이고, 화자는 KSS입니다. DDP를 사용한 모델은 정상적인 (a) alignment와 (b) mel spectrogram을 생성한 반면, SDP를 사용한 모델은 때때로 부자연스러운 (c) alignment와 (d) mel spectrogram을 생성하고 음성 중간에 긴 침묵이 생깁니다. |
|---|
 |
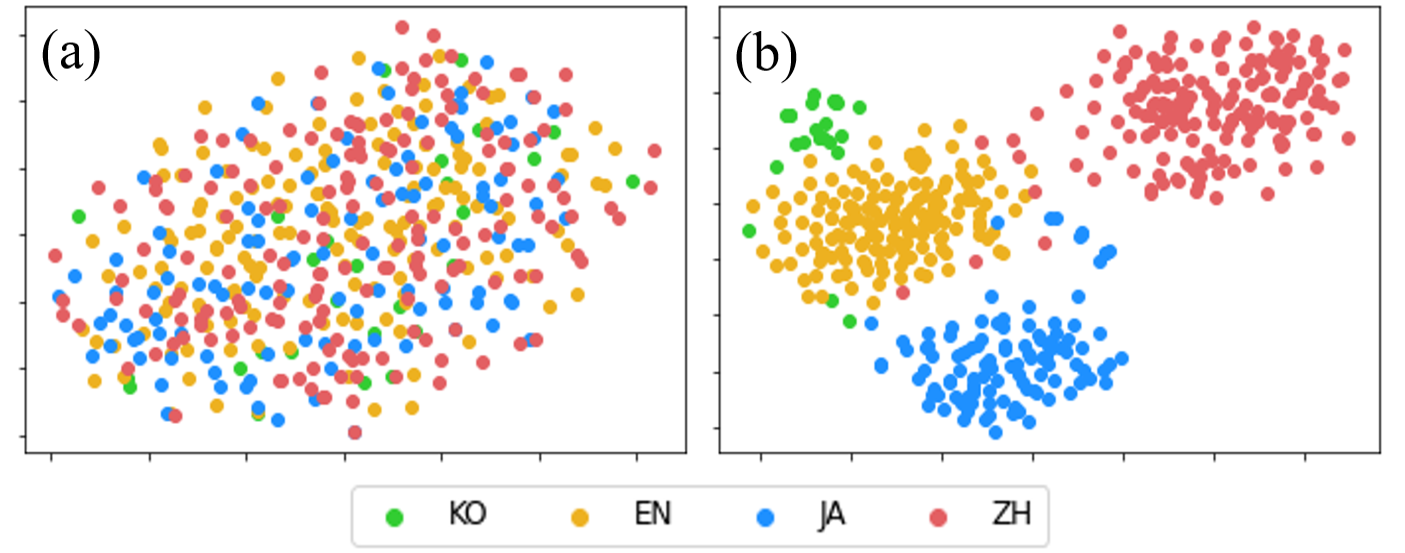
아래에 있는 Figure 4는 duration predictor의 hidden speaker representation을 t-SNE plot으로 그린 결과입니다. Speaker regularization loss를 사용하지 않은 (b)의 경우에는 같은 언어끼리 화자 정보가 뭉치게 되지만, speaker regularization loss를 추가한 (a)의 경우 언어에 상관없이 영벡터를 중심으로 분포하고 있습니다. 이 t-SNE plot은 다국어 TTS 모델에 speaker regularization loss를 추가하면 화자 정보가 언어와 분리되고 영벡터가 hidden speaker representation의 대표 역할을 할 수 있음을 보여주고 있습니다.
| Figure 4: (a) Speaker regularization loss 를 추가했을 때, (b) speaker regularization loss를 추가하지 않았을 때 472명의 모든 화자에 대한 duration predictor의 hidden speaker representation을 t-SNE plot으로 그린 figure입니다. |
|---|
 |
Audio samples
아래에 있는 표에는 SANE-TTS를 통해 합성한 다국어 음성들이 있습니다. 다양한 화자들이 4개 언어(영어, 한국어, 일본어, 중국어)의 text target을 읽고 있으며, 읽는 화자로는 영어 데이터셋에 있는 LJ와 LibriTTS4356, 한국어 데이터셋에 있는 KSS, 일본어 데이터셋에 있는 jvs001 그리고 중국어 데이터셋에 있는 SSB0073을 선택했습니다.
| Speaker | Reference Speech | English Target | Korean Target | Japanese Target | Chinese Target |
|---|---|---|---|---|---|
| LJ | |||||
| LibriTTS 4356 | |||||
| KSS | |||||
| jvs001 | |||||
| SSB0073 |
English Target: I saw him come from your window, and I saw all that passed between you in the balcony.
Korean Target (Romanization): 언젠가 들은 적이 있는 것 같거든요. (Eonjenga deul-eun jeog-i issneun geos gatgeodeun-yo.)
Japanese Target (Romanization): 許可書がなければここへは入れない。(Kyoka-sho ga nakereba koko e wa hairenai.)
Chinese Target (Hanyu Pinyin): 替我播放相思风雨中 (Tì wǒ bòfàng xiāngsī fēngyǔ zhōng)
Github sample page에는 SANE-TTS로 합성한 기본적인 다국어 음성을 포함하여 다른 다국어 TTS 모델과의 비교, ablation study 음성 샘플들이 있습니다. 약 500단어의 긴 문장을 자연스럽게 발화하거나, 논문에는 나와있지 않지만 code-switching이 적용된 음성 샘플들도 들을 수 있습니다.
Conclusions
저희 논문에서는 speaker regularization loss과 함께 cross-lingual speech synthesis 과정에서 speaker embedding 대신 영벡터를 집어넣는 방식을 제안했고, 그 결과 안정적이고 자연스러운 음성을 합성하는 다국어 TTS 모델인 SANE-TTS를 만들었습니다.
이상으로 긴 글 읽어주셔서 대단히 감사합니다. INTERSPEECH 2022에서 만나요!
References
- J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yang, Z. Chen, Y. Zhang, Y. Wang, R. Skerrv-Ryan, R. A. Saurous, Y. Agiomvrgiannakis, and Y. Wu, “Natural TTS Synthesis by Conditioning Wavenet on MEL Spectrogram Predictions,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 4779–4783. [arxiv]
- Y. Ren, Y. Ruan, X. Tan, T. Qin, S. Zhao, Z. Zhao, and T.-Y. Liu, “FastSpeech: Fast, Robust and Controllable Text to Speech,” in Advances in Neural Information Processing Systems, vol. 32, 2019. [arxiv]
- J. Kim, J. Kong, and J. Son, “Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech,” in International Conference on Machine Learning, vol. 139, 2021, pp.5530–5540. [arxiv]
- T. Nekvinda and O. Dusek, “One Model, Many Languages: Meta-Learning for Multilingual Text-to-Speech,” in INTERSPEECH, 2020, pp. 2972–2976. [arxiv]
- Y. Zhang, R. J. Weiss, H. Zen, Y. Wu, Z. Chen, R. Skerry-Ryan, Y. Jia, A. Rosenberg, and B. Ramabhadran, “Learning to Speak Fluently in a Foreign Language: Multilingual Speech Synthesis and Cross-Language Voice Cloning,” in INTERSPEECH, 2019, pp. 2080–2084. [arxiv]
- Y. Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, M. March, and V. Lempitsky, “Domain-Adversarial Training of Neural Networks,” Journal of Machine Learning Research, vol. 17, no. 59, pp. 1–35, 2016. [arxiv]
- E. Casanova, J. Weber, C. Shulby, A. C. Junior, E. Golge, and M. A. Ponti, “YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone,” arXiv preprint arXiv:2112.02418, 2021. [arxiv]
- Official source code of Meta-learning model: [github]